NVIDIA este lunes 17 reveló los detalles oficiales de la arquitectura de “Fermi” o GF100, la cual vendrá a reclamar el trono del rendimiento gráfico frente a la arquitectura de las Radeon HD 5800 basadas en el núcleo de Cypress, en el siguiente artículo técnico desmenuzamos ambas arquitecturas para que te enteres detalladamente que nos ofrecerá NVIDIA con Fermi frente a lo que ya ofrece AMD. Si bien son arquitecturas distintas y no comparables en términos numéricos, si nos sirve para darnos una idea de lo que nos ofrecen ambos bandos. Lectura recomendada.
NVIDIA está ultimando los detalles para lanzar su próxima arquitectura gráfica, que dará vida y fuerza a las tarjetas GeForce GF100, esta arquitectura también conocida como “Fermi”, será la primera en brindar soporte nativo para DirectX 11 por parte de NVIDIA y según hemos visto pretende dar un salta tanto cualitativo como cuantitativo respecto a la arquitectura actual (al menos eso insinúa en el papel), y de paso poder reclamar nuevamente el trono en el rendimiento gráfico arrebatado indiscutiblemente por AMD y las ATI Radeon HD 5800 series.
Describir una arquitectura es un asunto complejo, sobre todo si es una arquitectura gráfica, que es mucho más difícil de analizar que la arquitectura de un procesador por ejemplo, esto debido a que una GPU en cuanto a componentes es mucho más compleja que una CPU, debido a que tenemos asuntos altamente técnicos que no son sencillas de explicar y entender, pero como siempre haremos el esfuerzo de explicárles lo más claramente posible para que puedan entender desde ya que nos traerá “Fermi” entre sus entrañas.
Como mencionamos al inicio, las mejoras por parte de NVIDIA vienen tanto en el aspecto cuantitativo, por cuanto la cantidad de componentes se ha elevado en un gran porcentaje y también en el aspecto cualitativo agregando nuevas tecnologías como el soporte DirectX 11, mejoras en el tratamiento geométrico y también en el apartado visual y de calidad de imagen, el rendimiento en computo de propósito general también tiene inexorablemente un incremento sustancial (aunque no hay números por ahora)
Vemos en las siguientes paginas que nos ofrece Fermi, y de bonus agregamos lo que ya nos ofrecen las ATI Radeon HD 5800s en cuanto a arquitecturas.
Fermi: Especificaciones generales
Antes de entrar de lleno en la arquitectura y para tener un punto de comparación con las arquitecturas actuales tanto de NVIDIA como ATI veremos la siguiente tabla, para ir dimensionando y palpando lo que nos entregará NVIDIA con “Fermi” respecto a las otras arquitecturas.
Como puedes ver en la tabla de especificaciones, comparando la arquitectura actual de NVIDIA, el aspecto cuantitativo salta a la vista, de partida NVIDIA ha incrementado el número de procesadores shader o los “CUDA Cores” como les llama NVIDIA, debido a su versatilidad más haya de calcular “shaders”, sino que también como núcleos para cálculos de propósito general; bueno volviendo al tema, en este sentido “Fermi” tendrá un incremento del nada menos que un 115% pasando desde los 240 SP de la arquitectura del GT200 (GeForce GTX) a 512 “CUDA Cores”. (ya veremos como se organizan estos).
Otro cambio cuantitativo importante y estrechamente relacionado con la cantidad de núcleos es la escalofriante cantidad de transistores que traerá Fermi, son nada menos que 3.200 millones de transistores, comparado con los 1.400 millones del GT200 y los 2.154 millones de Cypress (Radeon HD 5800), sin duda este incremento en el numero de transistores va acorde con los cambios que se han hecho en la arquitectura como el ya mencionado incremento en los CUDA Cores y como podemos ver en la tabla, las unidades ROPs (que se incrementan a 48) entre otros cambios en el motor de operaciones geométricas que veremos más adelante.
GDDR5: Finalmente NVIDIA ha hecho el paso inexorable a memorias GDDR5, hasta la generación actual GeForce GTX 200 series (GT200) NVIDIA se había mantenido firme exprimiendo chips GDDR3, dándole en realidad poca relevancia al real beneficio de memorias GDDR5, algo que AMD viene ya usando desde hace dos generaciones gráficas RV790 (Radeon HD 4800) y Cypress (ATI Radeon HD 5800), ahora sólo falta ver a que velocidades fijará NVIDIA los chips GDDR5 de Fermi.
Quizás el único aspecto que llamara la atención es que NVIDIA utilizará una interfaz de memoria de 384-bit en lugar de los 512-bit de la generación actual. Esto básicamente se da por que Fermi incorpora sólo seis controladores de memoria de 64-bit, en lugar de los 8 del GT200, así: 6*64-bit= 384-bit, además el uso de memorias GDDR5 debería compensar esta disminución con sus altas frecuencias.
40nm by TSMC: Otro paso importantes que ha hecho NVIDIA para estar a la par con ATI, además de migrar a memorias GDDR5 y incorporar soporte nativo para DirectX 11, es utilizar un ya probado proceso de manufactura de 40nm, decimos ya probado porque su proveedor es TSMC (Taiwan Semiconductor Manufacturing Corporation), es el mismo que provee a AMD para sus Radeon HD 4000/5000 series y fue sabido los problemas que tuvo el gigante taiwanés para poder tener un buen rendimiento en la producción de silicio a 40nm, eso produjo una escasez de Radeon HD 4770 en su momento, pero TSMC ha mejorado los Yield y puede ya satisfacer sin problemas tanto a ATI como NVIDIA con nodos productivos a 40nm, el núcleo de Fermi (GF100) por lo tanto, estará fabricado en 40nm con los beneficios que ya hemos mencionado reiteradamente.
Comenzamos a desmenuzar la arquitectura de Fermi, en la siguiente imagen pueden ver el diseño general de Fermi, como así también una descripción de sus principales componentes, esto comparado con la arquitectura actual de NVIDIA (GT200), desde ya podrán ver que la nueva arquitectura a pesar de ser más compleja, tener muchos más componentes, está organizada de manera modular lo que la hace ver bastante ordenada en la ubicación y organización de sus componentes.
{kind=link}
La arquitectura de Fermi NVIDIA la ha organizado de la siguiente manera: en primer lugar el GF100 se compone como ya mencionamos de 512 CUDA Cores (SP), cada uno de estos 512 procesadores están organizados en 4 bloques individuales llamados Streaming Multiprocessors (SM), los cuales contienen 32 CUDA Cores, al mismo tiempo cada uno de estos SM está contenido en cuatro grandes bloques llamados GPC (Graphics Processing Cluster), exactamente lo que se muetra en la siguiente imagen.
Así que la ecuación para calcular los CUDA Cores es bien simple:
32 SP * 4 Streaming Multiprocessors * 4 Graphics Processing Clusters = 512 CUDA Cores.
Simplificado: 32x4x4 = 512
Fermi: Streaming Multiprocessors (SM): Ahora usaremos el microscopio para hacer un zoom en estos bloques o matrices que en su total suman 16 conteniendo en su interior 32 Cuda Cores, esto nos simplifica la ecuación anterior a 16SM*32SP=512CC, pero como veremos en la siguiente imagen hay otros componentes dentro de cada uno de estos bloques.
Como podemos ver (si amplían la imagen) en este bloque (16 en total) existen 32 CUDA (cuatro veces lo que ofrece el GT200), cada uno de estos procesadores posee su propia unidad de cálculos de punto flotante (FP Unit) y una unidad de calculo de enteros (INT Unit), especiales para cómputos de propósito general y cálculos matemáticos altamente complejos.
En cada bloque de Streaming Multiprocessors, encontramos otros elementos como las 4 unidades de textura, el “Raster Engine”, y un elemento bien importante como el “PolyMorph Engine” que luego detallaremos.
El diseño general de la arquitectura, NVIDIA dividió en cuatro grandes grupos llamados GPC (Graphics Processing Cluster), en lugar de uno solo como en la generación actual, metafóricamente hablando el GF100 es como una GPU Quad-Core con sus componentes organizados de tal forma que puedan tener la eficiencia y potencia necesaria para tareas de cómputo altamente demandantes, como geometría compleja en gráficos 3D y para eso incorpora renovadas unidades especializadas para el calculo geometrico.
El GF100 puede manejar shader complejos en aplicaciones altamente demandantes (como los juegos 3D), con suficiente potencia para manejar otras tareas GPGPU a través de los juegos o aplicaciones especificas, como por ejemplo simulaciones físicas vía PhysX, procesado de la IA (Inteligencia Artificial) e incluso avanzadas tecnologías de post-processing como depth-of-field (profundidad de campo), NVIDIA Surround / 3D Vision Surround, rasterizacion etc, nuevos niveles de filtrado etc. Por otra parte la arquitectura del GF100 soporta tecnologías como CUDA, PhysX, DirectCompute y OpenCL, permitiendo a los desarrolladores programar más que gráficos en sus aplicaciones.
Fermi: Arquitectura de Cache: Una de las principales características de las tarjetas actuales, es el nivel de paralelismo (ejecutar múltiples instrucciones al mismo tiempo) y sus capacidades gráficas, estas características están apoyada por la memoria cache en sus distintos niveles, que ayudan a administrar el trafico e instrucciones de datos, sean estos de computo o de gráficos, es un rol importante que siempre queda relegado a un papel secundario.
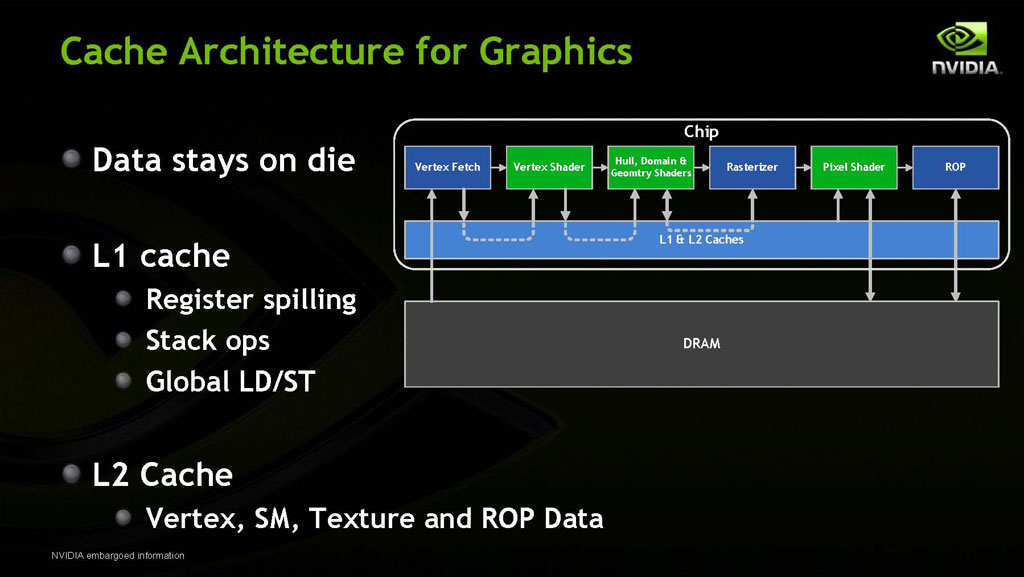{kind=link}
16/48 of Shared Memory: En la imagen siguiente ustedes pueden ver una ampliación del layout de la memoria y el cache, que se ubica justo debajo del bloque de Shader processors (CUDA Cores) en cada Streaming Multiprocessors (SM), para que lo entendamos debemos saber que cada SM tiene 64KB de cache compartido y programable, el cual puede ser configurado de dos formas: (1) Dejar 48KB como memoria cache compartida y otros 16KB como cache L1; y (2) Dejar 16KB como memoria cache compartida y otros 48KB como cache L1. Lo anterior es x3 veces lo que ofrece el GT200 (sólo 16KB), de aquí se denota la indicación de NVIDIA de “16/48 of Shared Memory”, su beneficio según NVIDIA es tener mas datos reusable entre los threads.
De la misma forma anterior el GF100 también puede destinar 16 o 48KB de cache L1 dedicado, lo que el GT200 carece, esto permite una mayor eficiencia en tareas como físicas (Physics) y operaciones de Ray Tracing.
Finalmente tenemos el cache L2 el cual se incrementa desde los 256KB a 768KB, pero a diferencia del GT200 donde este cache solo permite lectura en el GF100 este opera en lectura/escritura, esto permite mejorar el rendimiento para texturas y de computo. Con el cache L2 incrementado, NVIDIA puede por ejemplo mantener la mayoría de las funciones de renderizado de datos como la teselación (tessellation), sombreado (shading) y rasterizacion (rasterizing) en el mismo cache, en lugar de mover estos datos a la memoria o framebuffer (DRAM), esto beneficia el ancho de banda y alivia los cuellos de botella (bottlenecks) de la memoria, que ocurren por ejemplo cuando hay múltiples operaciones de lectura/escritura hacia el framebuffer.
Comparando el GeForce GF100 con la generación previa de NVIDIA, la arquitectura de cache del GT200 es inferior en varios aspectos, dede funciones hasta capacidad del cache, por ejemplo el GT200 sólo usa cache para texturas y posee cache L2 de solo lectura, en cambio el GF100 es reescribible y puede almacenar cualquier datos como vertexs, texturas, ROPS etc. Ahora comparado con las Radeon HD 5800 series, ATI vacía toda la información a la memoria o framebuffer y luego los devuelve a los núcleos (stream processors) para el proceso de resterizacion de salida, esto causa una baja en la eficiencia y rendimiento, en cambio NVIDIA mantiene todos estos datos en el cache evitando así latencias en las memorias para estos procesos.
Esto trae como beneficio para el usuario final básicamente una mejor eficiencia en el sistema de memorias, ya que ocupamos menos ancho de banda debido a que las peticiones de lectura/escritura se mantienen en el cache, esto beneficiará al GF100 por ejemplo a altas resoluciones, con filtrados de imágenes de alta calidad, donde el framebuffer puede ser fácilmente saturado.
Fermi: Raster Engine & PolyMorph Engine:
Uno de los cambios importantes hechos por NVIDIA en el diseño interno de la arquitectura del GF100, no solo ha sido mejorar el rendimiento de computo incrementando en un 115% el numero de procesadores, el aspecto geométrico de toda índole es una de las mejoras que NVIDIA mas ha enfatizado con la nueva arquitectura, según la compañía este rendimiento se ha incrementado x8 veces respecto a la generación previa (GT200), esto gracias a nuevos y mejorados motores los cuales ha sido reubicados para un mejor rendimiento, la calidad de imagen es algo en lo que tambien enfatiza NVIDIA, el rendimiento en tareas de calculos de físicas (PhysX)
En efecto si comparamos la arquitectura de la GeForce GTX basadas en el núcleo GT200, la cual analizamos en su momento en este artículo, veremos que NVIDIA ha movido los motores gráficos o geométricos a un lugar mucho más cercano a los CUDA Cores, esto materializado en los nuevos motores “Raster Engine” y el “PolyMorph Engine” que en lugar de estar en la periferia de la arquitectura como en el GT200 ahora están en cada Streaming multiprocessors (SM) y Graphics Processing Cluster (GPC) respectivamente. Para que quede más claro observen la siguiente imagen:
Como podemos ver en la imagen precedente cada GPC tiene su propio “Raster Engine” (4 en total) y cada uno de los 16 SM posee su propio motor PolyMorph Engine (16 en total), de esta manera NVIDIA distribuye y balancea de mejor forma la carga geométrica para un rendimiento más balanceado y eficiente. Esto según la compañía provee un renderizado secuencial más fluido e incrementa el rendimiento geométrico en el tratamiento de pixel/shader/vertex por 8 veces, respecto a lo que ofrece por ejemplo el engine geométrico del GT200.
PolyMorph Engine: Dentro de los dos nuevos motores o unidades de ejecución, el más importante o al que se le ha dado mayor relevancia NVIDIA es al “PolyMorph Engine”, que es el motor que administra el apartado geométrico del GF100, el PolyMorph Engine es el responsable de manejar asuntos como Vertex Fetch, Tessellation, Viewport Transform, Attribute Setup y Stream Output, es justamente aquí donde esta ubicado la unidad de teselacion, uno de los grandes cambios que DirectX 11 trajo y que ATI tanto enfatizo con sus Radeon HD 5800 series.
Como ya mencionamosel GF100 trae 16 de estos motores, uno asignado a cada Graphics Processing Cluster (GPC) por lo que están muy relacionados con los CUDA Cores, también son 16 las unidades de teselacion, en comparación con el GF200 que no traía unidades dedicadas para teselacion. Este motor por lo tanto es clave para las tareas de teselación del GF100 y que le permitirá además tener la potencia y aceleración por hardware necesaria para los efectos de teselación que se puede lograr con DirectX 11.
Raster Engine: Sin muchas novedades y opacado por el PolyMorph Engine, el Raster Engine también han sido movidos más cerca de los CUDA Cores, pero de manera más general y compartida, puesto que el GF100 posee cuatro de estos motores uno asignado a cada bloque Graphics Processing Cluster (GPC). En el GT200 por ejemplo, había una solo bloque para estas operaciones o Raster Engine.
Como pueden apreciar en la imagen, cada Raster Engine posee las unidades relacionadas con operaciones de rasterización, proceso por el cual una imagen en formato vectorial se convierte en un conjunto de pixeles y punto que son desplegados en pantalla. El raster Engine recibe y transforma los datos enviados desde el PolyMorph Engine.
NVIDIA se ha tomado bastante enserio el asunto de tratamiento geométrico, no por nada mencionan que Fermi es x8 veces más potente gráficamente que la actual generación de tarjetas gráficas basadas en el GT200, posiblemente también tenga una mayor potencia grafica que las Radeon HD 5800, por que como podrán ver mas adelante en este articulo técnico en la sección correspondiente a la arquitectura de las Radeon HD 5800s, NVIDIA ha incorporado nada menos que 16 unidades para teselacion, mientras la arquitectura de las Radeon HD 5800 (Cypress) incorpora solo una unidad dentro del “Graphics Engine”, pero no nos adelantemos, ya que como mencione al inicio son arquitecturas diferentes y no comparables número a número
Fermi: NVIDIA Surround / 3D Vision Surround
Estas dos tecnologías son los “eye candy” que trae Fermi con el núcleo GF100, son en parte la respuesta a la tecnología multi-display ATI Eyefinity, conservando las proporciones pues el soporte de NVIDIA en cuanto a monitores se queda un poco atrás respecto a la apuesta de ATI además exigen necesariamente más de 1 tarjeta gráfica.
NVIDIA Surround:
Esta tecnología en realidad es un intento de tener una respuesta a ATI Eyefinity, pero al parecer NVIDIA se ha quedado algo corto, pues NVIDIA Sorround, tal como se muestra en la imagen permite administrar independientemente 3 monitores los cuales deben ser alimentados por una configuración SLI, si correcto debes usar a lo menos 2 tarjetas para alimentar 3 monitores al mismo tiempo, lo bueno es que la tecnología no es exclusiva de “Fermi”, ya que será retro-compatible con las GeForce GTX 200 series. Esta tecnología puede administrar hasta 3 monitores con una resolución de 2560×1600 pixeles, nada que en lo personal me impresione mucho, puesto que la apuesta de ATI me parece mucho más versátil, pues con un sola tarjeta puedes hacer eso y más y alcanzar resoluciones mucho más altas.
La razón del porque una configuración SLI es necesaria es por que tanto las GeForce GTX 200 series y las GF100 solo pueden tener activos un par de monitores al mismo tiempo, además para administrar resoluciones altas, necesitamos mucho poder, pero esto mas parece una escusa por que se supone que Fermi debería tener suficiente potencia para esto.
3D Vision Surround:
Básicamente lo que pretende NVIDIA con esta técnica es sumergirnos en juegos en 3D, agregando visualización estereoscópica, para esto necesitamos lógicamente el KIT NVIDIA 3D Vision, un monitor con una frecuencia de refresco de 120Hz, esto funciona además en conjunto con NVIDIA Surround y por ende exige lo mismo, configuración SLI de GeForce GTX 200 o GF100.
Fermi: Documentación Oficial
Si quedaron con gusto a poco luego de leer las páginas anteriores, cosa que dudamos, les dejamos la documentación técnica oficial que proporcionó NVIDIA respecto a las novedades de Fermi, la calidad de imagen y filtrado fue uno de los asuntos que no alcanzamos a detallar, pero dejamos los documentos oficiales para que ustedes mismos puedan echar un vistazo. Hay también gráficos de rendimiento, pero como siempre hay que tomarlos con una cuota de escepticismo y no confiarnos hasta ver pruebas de rendimiento reales.
GF100 Processor Architecture I
[nggallery id=413]
GF100 Processor Architecture II
[nggallery id=414]
GF100 Compute For Gaming
[nggallery id=416]
GF100 Image Quality
[nggallery id=415]
Con esto finalizamos el apartado técnico referente a “Fermi”, y preparen sus pupilas por que ahora pasaremos a analizar “Cypress”·
La familia tope de línea de tarjetas gráficas de AMD la componen la Radeon HD 5970 (doble-GPU), la Radeon HD 5870/5850, pronto podía sumarse la Radeon HD 5830, siendo estos los buques de batalla más poderosos de la armada DirectX 11 de AMD y con las cuales la compañia reina sin competencia el mercado de las tarjetas gráficas. Todas ellas se basan en la misma arquitectura.
Ahora aclaramos un punto, ¿Por qué comprar ATI cuando NVIDIA ha barrido el piso con ellos en rendimiento absoluto durante las últimas tres generaciones y está construida sobre la arquitectura del RV770 en vez de crearse desde 0? Elemental mi querido Watson, si bien la arquitectura no es 100% nueva ATI lo que hizo en esta ocasión fue prácticamente tomar algo que ya funcionaba a la perfección y darle duro en el único punto negativo que ésta tenía: el rendimiento absoluto. Asi hizo algunos ajustes en la arquitectura, la cual analizaremos en profundidad de aquí en adelante.
ATI de partida aumentó la cantidad de transistores desde los 956 millones que la anticuada Radeon HD 4870 tiene, a la enorme suma de 2.150 millones de transistores. Por otra parte la inclusión de tecnologías propietarias de ATI como Eyefinity, Stream Computing, CrossfireX, UVD y otras, de seguro hará que más de alguno quiera cambiarse al lado rojo simplemente para poder controlar varios monitores y resoluciones extrañas sin problema alguno, aunque en la realidad esto no tiene mucha veracidad, puesto que la gente que lee estos artículos es más inteligente a la hora de comprar y no compra una tarjeta por el hecho de que se pueden conectar mil monitores, sino que elige por precio/rendimienot.
Por otra parte tenemos a Windows 7, DirectX 11 y sus tecnologias asociadas (Shader Model 5.0, DirectX Compute, etc), la API favorita de gran parte de los desarrolladores de videojuegos en el mundo que promete popularizar todas las mejoras que DirectX 10 nunca pudo gracias a la poca aceptación de Windows Vista. Por supuesto nadie quiere ser el “pobretón” con una VGA vieja en el sistema operativo más hot de la temporada, por lo que es otro gran cause por el cual atraerán a más consumidores.
Bueno, ahora si… luego de leer el apartado técnico respecto a Fermi, esperamos que le queden ojos para leer el apartado técnico respecto a Cypress.
ATI TeraScale 2 Architecture:
Si bien es cierto, la arquitectura de hardware «TeraScale 2» de “Cypress” en adelante RV870, tiene muchos elementos en común con la arquitectura “TeraScale” de primera generación del RV770, AMD en virtud de mejorar el desempeño y prestaciones de la nueva generación de tarjetas gráficas ha hecho varios cambios tanto cualitativos como cuantitativos. En el primer caso estos están concebidos en virtud de soportar las nuevas tecnologías y funciones de la cual hace gala con esta nueva generación y los cambios cuantitativos que se expresan en fríos y escalofriantes números, como el exponencial aumento de transistores, el incremento x2 del numero de procesadores de flujo, el incremento de ancho de banda de las memorias, el incremento de frecuencias, texturas, Rops, etc, cambios que proveen a simple vista una potencia inigualable a la nueva tarjeta de AMD.
RV870 (Crypress) |
–
Proceso de manufactura a 40nm: Una de las novedades de la nueva generación de tarjetas, es el proceso de fabricación a 40nm de segunda generación, factoría de la taiwanesa TSMC (Taiwan Semiconductor Manufacturing Corporation), un proceso que ya está refinado, pero que no estuvo exento de problemas cuando se testearon los primeros nodos y silicio con este nanometraje, pero que la fundición oriental pudo superar con éxito. De todos modos los 40nm no son una novedad para AMD en el mercado gráfico, ya que primero debuto con gráficas a 40nm en el mercado móvil y luego en el mercado de escritorio con la escurridiza Radeon HD 4770 (RV740), pero lo que si marca la novedad es que es la primera vez que AMD utiliza este proceso de manufactura en tarjetas tope de línea para el mercado “high end”. Los beneficios de un proceso de manufactura de reducido nanometraje ya las hemos comentado anteriormente como el consumo, disipación térmica, reducción de costos de producción y mayor rendimiento por wafer u oblea de silicio, aunque en la práctica cuesta un poco notar estas diferencias.
–
1. Motor gráfico (Graphics Engine): No podemos entrar de lleno a los shaders si no conocemos el resto de la arquitectura. El “Command Engine” ubicado en la parte superior del núcleo es el encargado de realizar la lista de tareas con lo que hay que mostrar en pantalla al realizar una maqueta tridimensional que debe ser coloreada por los Stream Processors. Es este motor en donde ocurren maravillas como la teselacion, rasterización (convertir vectores en pixeles) y otras tareas como filtrar los pixeles que no deben renderizarse en la escena. Algunos de los cambios que han hecho los ingenieros de ATI en el RV870, es incorporar doble unidad de rasterizacion o “Rasterizer” (el RV770 posee solo una), una nueva unidad de teselación (Tesellator) ahora programable vía DirectX 11 con “hull & domain shaders”, la incorporación de un nuevo algoritmo que puede reducir aberraciones graficas o artifacts, además de estar preparado para dar soporte a las nuevas características de DirectX 11 que detallaremos en el apartado correspondiente.
Cabe mencionar que las tarjetas ATI Radeon han tenido unidades de telesacion por varias generaciones, también en la GPU de la Xbox 360, pero estas unidades no eran muy utilizadas por los desarrolladores debido a que las versiones previas de DirectX no explotaban como era debido sus capacidades. Recién ahora con DirectX 11 la unidad de teselacion viene a tomar un papel protagónico en esta API, donde los desarrolladores pueden hacer uso de estas unidades para programar mediante dos nuevos tipos de shader incluidos en DX 11, que son “Hull shader” (que calcula efectivamente el nivel de teselacion requerido antes de pasar a la unidad de teselacion misma) y “Domain shader” (que envía los datos teselados como vértices para el proceso de renderizado final). Pero estas características no son las unicas, puesto que la unidad de telesacion puede también manejar algoritmos como Catmull-Clark en una sola pasada, además puede ajustar el nivel de detalle geométrico en tiempo real logrando paisajes y sobretodo personajes con un mayor detalle gracias al realce gráfico que produce la unidad de telesacion.
Finalmente, para los que son observadores notaran en el motor grafico del RV870 la ausencia de la tradicional unidad de interpolación (interpoation unit), esto básicamente por que sus funciones han sido reemplazadas por el procesador de shader (shader processors). AMD por lo tanto, ha añadido las instrucciones de interpolación a sus “shader cores” o núcleos de sombreado, agregando para esto una nueva características DirectX 11 llamada “pull-model interpolacion”, que entrega a los desarrolladores con control mas directo sobre las funciones de interpolación, agregando esta función al motor de sombreado se logra una precisión matemática mucho mas alta que a la implementación anterior. El rendimiento OpenGL también ha sido mejorado dentro de este motor para renderizado gráfico, además de agregar 12-bit subpixel precisión.
–
2. Nuevo diseño: Al examinar una gráfica del diseño (layout) de la arquitectura interna del RV870 y la comparamos con la arquitectura del RV770, lo primero que nos llamara la atención es el nuevo diseño para agrupar los “stream processors”, se hace evidente que ante el incremento exponencial de núcleos se hizo necesario rediseñar y optimizar la estructura para hacerla más eficiente, dividiendo la “matriz” en dos particiones que agrupan 800 procesadores cada una, estas particiones almacenan datos en un cache global denominado “global data share” y luego envían estos a un cache de L2 por interfaces como el “Data request bus” y el “Crossbar”, antes de ser enviados al controlador de memoria. Elementos no nuevos que ya se encontraban en el diseño del RV770, solo que ahora en lugar de ser periféricos (como en el RV770), son interfaces centralizadas y compartidas para ambas particiones de SIMD Engines.
–
3. SIMD Cores o SIMD Engines: Como ya lo vimos con el RV770, AMD organiza cada uno de los procesadores de flujo (Stream processors) en bloques que AMD denomina “SIMD Cores”. Haciendo una analogía esto es similar al cluster TPC (Texture Processing Clusters) de las tarjetas NVIDIA GeForce 200 series que utiliza el método de procesamiento SIMT (Single Instruction, Multiple Thread) para lograr administrar miles de hilos o thread de manera independiente y así lograr paralelismo, por su parte AMD con el núcleo RV870, está utilizando el método SIMD (Single Instruction, Multiple Data), tecnología utilizada por años en los procesadores para computadores y que permite procesar con una sola instrucción múltiples datos, la verdad esto no ha cambiado mucho por que desde el RV770 que utiliza SIMD, la diferencia está ahora en el numero y es lo que pasamos a explicar en el siguiente párrafo.
Una de las razones del incremento en el numero de transistores del RV870 (2154 millones) frente al RV770 (956 millones) son estas unidades o microprocesadores de flujo (Stream processors) elementos claves capaces de ejecutar instrucciones complejas a una gran velocidad y de manera dinámica. En términos numéricos desglosar los 1600 núcleos del RV870 es una operación sencilla (claro para quien ya está familiarizado con la arquitectura), para esto debemos considerar que el RV870 contempla 20 “SIMD Engines” (en rojo) -divididos en 2 grupos de 10 unidades-, los cuales agrupan 16 bloques o clusters que contienen a su vez 5 “Stream Cores”, de estas 5 unidades, hay una que cumple una función especial que puede administrar sólo operaciones matemáticas de punto flotante de 32-bit FP MAD (Multiply and Add) en un ciclo de reloj, con otras instrucciones complejas como SIN, COS, LOG, EXP, etc, las restantes cuatro unidades, además de cálculos en 32-bit, también pueden realizar cálculos en 64-bit, tal como se muestra en la siguiente imagen:
Todos estos mini-procesadores proporcionan a la tarjeta de un poder de computo de 2.7 TeraFLOPS (operaciones de punto flotante por segundo), cuando se utiliza cálculo de precisión simple (FP32) y aproximadamente 544 GigaFLOPS para cálculos de doble precisión (FP64). Esto comparado con los 1.2 TeraFLOPS de potencia del RV770, lo que nos indica que con el doble de núcleos, el RV870 a su vez entrega un extra de rendimiento comparado con el chip anterior, y más potencia que cualquier tarjeta gráfica de mercado, sea single o dual, lo que nos habla de una mayor eficiencia en este sentido.
Ahora, para determinar el número total de stream processors, solo debemos hacer una simple multiplicación:
RV870: 20 SIMD Engines * 16 clusters * 5 stream cores = 1600 Stream processors.
RV770: 10 SIMD Engines * 16 clusters * 5 stream cores = 800 Stream processors.
A diferencia de NVIDIA donde sus Stream Processors siempre se mantienen constantes, éstos son dinámicos en el lado rojo y la cantidad y tamaño de las instrucciones que enviemos al núcleo puede disminuir la cantidad de Stream Processors que estén disponibles. De todos modos tanto los shader/núcleos/cores de ATI y NVIDIA trabajan de manera distinta, así que no son comparables cuantitativamente.
Por otra parte el costo de incrementar el número de transistores y SP, trae como consecuencia el inevitable incremento en el tamaño físico del chip, a pesar de usar un proceso de manufactura de 40nm, la mayor cantidad de unidades hace crecer el RV870 a 334mm2, desde los 263mm2 del RV770, algo no muy conveniente para disipar temperatura debido al mayor área.
–
4. Mejoras internas: Si bien es cierto el RV870 ha incrementado el numero de elementos dentro de sus propia arquitectura, las mejoras no solo son a nivel macro, si hilamos más fino, veremos que las mejoras en transferencia entre los componentes internos no son nada despreciables. Por ejemplo cada uno de los 4 bloques de cache L2 asociados al controlador de memorias han sido incrementado desde 64KB a 128KB, mientras el cache L1 de 8KB asociado cada SIMD Cores puede transferir datos al cache L2 a 435GB/s, esto comparado con los 384GB/s del RV770. En este mismo contexto el cache L1 tiene una tasa de transferencia de 1TB/s a la unidad de filtro de texturas (texture filters) un incremento de 2x desde los 500GB/s del RV770.
Por otra parte el tamaño total del “global data share” ha sido cuadruplicado de 16KB a 64KB y el ancho de banda de las memorias que se define como la tasa de transferencia de datos entre el cache L1 y el controlador de memorias, se ha incrementado hasta la impresionante cifra de 153.6GB/s, superior al RV770 que en este sentido consigue 115GB/s con la Radeon HD 4870 y 124.8GB/s con la Radeon HD 4890.
–
5. Unidades de Texturas (Texture Units): Como consecuencia del incremento de stream processors, las unidades de texturas son otra de las mejoras importantes dentro de la arquitectura del RV870, respecto al RV770, puesto que estas unidades tal como los Stream Processors, han sido incrementadas y mejoradas. Ahora contamos en total con 80 unidades de textura, 4 por cada SIMD Engine, esto es el doble que la generación anterior, pero incrementar el numero de texturas no es lo único, puesto que también ha incrementado el poder de calculo geométrico de cada una pudiendo procesar hasta 68 billones de texeles bilineares por segundo y 272 billones 32-bit fetches/segundo.
–
6. Controlador de Memoria: Para el controlador de memoria, AMD mantiene el mismo layout que el controlador de memoria del RV770, donde abandono la topología ring-bus para integrar un Hub que administra el tráfico desde los chips de memorias a otras interfaces como el motor UVD2, las interfaces de video, PCI Express y el compositor CrossFireX. Hasta aquí nada nuevo respecto al RV770, las novedades están en que ahora las memorias para poder soportar altas frecuencias sin sobresaltos, incorporan código de detección de errores o EDC (Error Detection Codes), muy similar al en su finalidad al ECC (Error Correction Code) de las memorias DRAM para servidores. Una característica indispensable talvez no tanto para los juegos, pero sí para el overclock y aún más importante para las aplicaciones generales que utilizan la GPU como Photoshop o software de encodeo de video. Este código de detección de errores nos permitirá evitar –valga de redundancia- errores en los datos de la memoria cuando se aplican altas frecuencias, evitando por ejemplo “atifacts” y “freezeos” (congelamientos de imagen) o reinicios del SO a causa de estas anomalías. Permitiendo un funcionamiento mucho mas estable y robusto de la tarjeta de video.
En cuanto a aspectos cuantitativos, el RV870 incorpora 4 controladores de memorias de 64-bit que alimentan 2 interfaces de memorias de 32-bit, es decir, cada controlador alimenta 2 chips de memoria lo que nos da una interfaz de 256-bit (4*64-bit o 8*32-bit), tal como el RV770, pero ahora utilizando chips de memorias GDDR5 de quinta generación con una tasa de transferencia de 4.8Gbps un incremento sustancial respecto a los 3.6Gbps de las memorias usadas en el RV770, en cuanto a frecuencias, las memorias de la Radeon HD 5870 vienen fijadas a 1200Mhz nominales o 4800Mhz efectivos, con un ancho de banda de 153.6GB/s, las frecuencias mas altas hasta ahora en una tarjeta gráfica.
–
7. Render Back End (ROPS):
–
Las unidades ROPS o Render Back-End como los ha llamado AMD, han tenido importantes mejoras respecto a la generación anterior, de partida y como ya ha sido usual en la arquitectura estas unidades se han duplicado, para que quede mas claro, el RV770 posee un total de 16 ROPs, distribuidas en 4 particiones con 4 ROPs cada una, ahora en cambio el RV870 posee un total de 32 ROPs, distribuidas en 8 particiones con 4 ROPSs cada una. Con este incremento el RV870 consigue un mayor rendimiento cuando se aplican filtros como anti-aliasing (AA), especialmente en el modo MSAA (Multisampling Antialiasing) estas mejoras han consistido básicamente en incrementar el rendimiento de píxeles por clock en los distintos modos y niveles de filtrado MSAA respecto al RV770, así por ejemplo cuando se aplica filtro MSAA en los niveles 2x/4x, el RV870 puede procesar 32 píxeles por clock, comparado con el RV770 que solo puede lograr 16 pix/clock y en general en la mayoría de los niveles de filtrado el RV870 incrementa y dobla el rendimiento que puede lograr el RV770. Esto queda bastante claro, al menos en el papel, con la siguiente imagen:
Desde luego el poder aplicar filtros con este nivel de precision, penaliza notablemente el rendimiento, aunque AMD está muy orgulloso de que esta perdida sea minima comparado con el lado verde, ya que cuando se pasa de un filtro 4xAA a uno de 8xAA, la Radeon HD 4870 “sólo” perdería un 18% de rendimiento, mientras una tarjeta NVIDIA pierde un 50%, pero seamos escépticos al respecto pues la recomendación viene muy de cerca y generalmente mucho de lo que vemos en el papel no lo percibimos en la práctica.
Tecnología Eye Infinity:
La tecnología multi-display Eye Infinity de AMD (que ya adelantamos en esta nota), es una de las novedades que ha incorporado la compañía en la nueva familia de tarjetas graficas respecto a la generación anterior, este “plus” es totalmente nuevo y no estaba presente en el RV770, pero ¿cual es la finalidad o en que consiste esta tecnología?
Antes de continuar con el tema netamente técnico, AMD quiere enfatizar en la importancia de la “computación panorámica” para ayudar a mejorar la productividad y la multitarea con gráficos innovadores a través de distintos espacios de trabajos en una sola estación de trabajo, algo no nuevo en la industria y que podemos encontrar en áreas especificas como el área financiera, medica, de investigación y estudios de postproducción y animación entre otros rubros, pero que poco a poco AMD pretende convencernos de que ya no vasta sólo un monitor o LCD para trabajar o jugar, AMD quiere convencernos que la experiencia de juego o trabajo puede mejorar ostensiblemente con una configuración multi-monitor con la que podemos conseguir resoluciones ultra-altas, en teoría podríamos alcanzar resoluciones de hasta 8192 x 8192 pixeles, equivalente a 67.1 megapíxeles de resolución, 7680 x 3200 (24.6 megapíxeles) o 4800 x 2560 (12.3 megapíxeles), entre otras resoluciones dependiendo de la configuración multi-display que conformemos. Entre las cuales tenemos:
Entrando en el tema netamente técnico, la tecnología multi-display Eye Infinity como ya dijimos en una novedad con el RV870, ya que además de las típicas salidas de video como VGA (D-Sub), DVI y HDMI que son gestionadas por su respectivo controlador, AMD ha incorporado en el RV870 un controlador exclusivo para esta tecnología, el cual puede soportar hasta 6 salidas de video mediante conexiones DisplayPort, un estándar que poco a poco comienza a masificarse en el mercado, pero estas salidas son independientes, es decir, en cada uno de estas 6 salidas, es posible administrar un escritorio o entorno de trabajo distinto, así en un LCD puedes ejecutar un juego, en el otro navegar por Internet, en otro trabajar con aplicaciones ofimáticas y así sucesivamente, pero también es posibles combinar estas salidas de video para conformar un gran escritorio en distintas configuraciones para por ejemplo reproducir un video en alta calidad o ejecutar un juego con un ángulo de visión que no alcanzarías con un monitor o LCD convencional. Además es posible utilizar las otras salidas de video D-Sub, DVI o HDMI para combinar uno o dos pantallas adicionales, todo esto se puede configurar y administrar fácilmente mediante el ATI Catalyst Control Center que se incorpora con los drivers ATI Catalyst.
Desde luego estas configuraciones requieren el software y hardware necesario, en primer lugar esta tecnología es sólo compatible con sistemas operativos Windows Vista y Windows 7, además de Linux, soporte que se dará en futuras versiones de los drivers ATI Catalyst, el segundo caso el harware que necesitamos partimos con monitores LCD con conexión DisplayPort, además de una edición especial de la Radeon HD 5870 “Infinity Edition” que además de las salidas de video comunes (VGA (D-Sub), DVI y HDMI) incorpora físicamente 6 salidas DisplayPort, tarjeta que más adelante AMD introducirá en el mercado, ya que la actual Radeon HD 5870 no las posee.
Algunas pantallas LCD que poseen conexión DisplayPort son las siguientes: Dell 3008 – Dell U2410 – Dell 2408 – Dell P2010H – Dell P2210H – Dell P2310H – NEC MultiSync EA231WMi-BK – HP LP2480zx – HP LP2475w – HP LP2275w – Lenovo 2440x
AMD toma ventaja significativa respecto a su rival NVIDIA, con el tema de DirectX 11, ya que es el primero y único con hardware DirectX 11 y pone en manos de los desarrolladores de videojuegos, el hardware necesario para comenzar a desarrollar títulos DirectX 11, una ventaja que no se veía desde que lanzo la Radeon 9700, mucho antes de que saliera DirectX 9. Ahora se da un caso similar con el tema de DirectX 11, pues AMD un mes antes de que salga oficialmente Windows 7 con soporte nativo para esta API, ya posee el hardware compatible. De seguro los desarrolladores de videojuegos utilizaran hardware AMD (ATI) para comenzar a desarrollar sus títulos.
¿Pero que nos trae la nueva API?, DirectX 11 es uno de los cambios más significativos desde DirectX 10, esta API trae importantes mejoras tanto para los desarrolladores como para los jugadores más exigentes, con optimizaciones y nuevas características que mejoran las prestaciones de las versiones anteriores como DirectX 10 y la API de transición DirectX 10.1. Con un rediseño en su arquitectura permiten a DirectX 11 sacar el máximo rendimiento a las actuales arquitecturas gráficas, los beneficios visuales y gráficos también se ven favorecidos con las nuevas características.
En lo que a avances tecnológicos se refiere, DirectX 11 se enfoca en cinco puntos principales para aprovechar de una mejor -y más eficiente- manera nuestro hardware, hablamos de: La teselación por hardware, Direct Compute/Compute Shaders, HDR texture compression, soporte multi-threading y Shader Model 5.0.
1. Teselacion:
Para los gamers la teselación por hardware es lo más significativo que veremos al tener una nueva forma de trabajar para crear modelos más detallados en todo sentido de la palabra. Al teselar realizas polígonos complejos utilizando diversas formas en ángulos y tamaños diferentes para cada parte del modelo a renderizar como en la siguiente imagen.
En la serie HD 5000 los teseladores no pueden ser accesados directamente por hardware, sino que la malla poligonal pasa por una unidad llamada «Hull Shader» encargada de determinar los puntos en los que se puede teselar el polígono, información enviada al «Tesselator» para que tome los polígonos simples que se le entregan y los convierta en unidades más complejas y con mayor nivel de detalle. Paralelamente el «Hull Shader» envía los mismos datos al «Domain Shadder» para que se asegure de que no hayan desplazamientos erróneos o algún tipo de error entre cómo se debiera ver la imagen y lo teselado.
Lamentablemente las unidades de teselado en las Radeons anteriores (serie 9000 en adelante) no pueden ser utilizadas debido a que sólo puedes acceder a estas mediante instrucciones especiales, lo que convertiría a los juegos en títulos exclusivos para tarjetas ATI. Los «ports» llevados al PC desde la XBOX 360 por su parte ya no debieran venir tan horrible y asquerosamente mal optimizados como GTA 4 debido a que la «blanquita de los anillos rojos» es capaz de realizar el teselado de una forma bastante similar que requiere poco trabajo para pasarlo a DX11.
2. Direct Compute:
El otro gran cambio es Direct Compute o Compute Shaders, dependiendo desde donde se le mire. Esta es la respuesta oficial de Microsoft a OpenCL, ATI Stream, NVIDIA CUDA y cualquier ambiente de programación para GPGPU de terceros para realizar cálculos mágicos como físicas, ray tracing o inteligencia artificial aprovechando el alto poder de procesamiento de instrucciones paralelas que una GPU tiene contra una CPU. En caso de utilizar la GPU para cálculos no gráficos fuera de DX11 como al encodear un video estaremos hablando de Direct Compute.
Las bondades de Direct/Compute Shaders podrá ser aprovechada por GPUs que soporten DX10 en adelante, aunque no esperen que una GeForce 8400GS acelere de igual manera el encodeo de un video en H.264 como un CrossFireX de 5870×2. Mientras tanto los usuarios de OS X, Linux y Windows XP tendrán que chuparse el dedo a menos que los programadores deseen usar OpenCL para el uso de GPGPU y las extensiones de OpenGL (la teselación aún no es parte del núcleo de éste) para entregar contenido de calidad que no esté amarrado a plataformas en específico.
3. Compresión de Texturas HDR.
Tanto DirectX 10 y 10.1 no poseían compresión de texturas HDR, DirectX 11 introduce esta nueva característica orientada principalmente a los desarrolladores, pero que de igual forma favorecerá a los jugadores, a través de un renderizado de gran calidad sin penalizar el rendimiento en el consumo de ancho de banda de memorias. DirectX 11 incluye dos nuevos bloques de compresión de texturas que son BC6H y BC7 (Block Compression). BC6 permite una compresión en una razón de 6:1 en texturas HDR (High Dinamic Range) de 16-bit con soporte para descompresión por hardware. Por su parte BC7 provee una compresión en una razón de 3:1 en texturas normales (LDR low dynamic range) de 8-bit. BC7 incluso utiliza un método de compresión sin perdida de calidad respecto a los formatos de compresión anteriores BC3/DXT5. Un ejemplo podemos observarlo en la siguiente imagen, donde se muestra el método de compresión BC7 vs BC3.
Las ventajas de agregar este sistema de compresión tiene una incidencia en el rendimiento en tareas que demandan muchos recursos y potencia gráfica (como el HDR), sin sacrificar velocidad y por lo tanto sin entorpecer la experiencia de juego, al mismo tiempo que obtenemos imágenes y gráficos foto realistas. Los desarrolladores por su parte pueden aplicar texturas más grandes en virtud de espacio en memoria que se ahorra cuando se comprimen texturas.
4. Multi-threaded rendering.
Tal como ha pasado con los procesadores dual, triple y quad-core, la computación gráfica también ha pasado de una arquitectura single-thread a una arquitectura multi-núcleos, con cientos de microprocesadores capaces de ejecutar varias instancias al mismo tiempo, pero tal como en el caso de los procesadores, si no poseemos el soporte a nivel de software (API, Drivers y SO), poco es el beneficio que se le puede sacar a estas mejoras. Tanto ATI como NVIDIA desde hace algunas generaciones que poseen arquitectura escalable y GPUs multi-núcleos, pero sin la respectiva API gráfica que explote sus capacidades multi-hilo no tiene mucho sentido, tampoco si no se proveen los drivers con el respectivo soporte.
Es por lo anterior y en virtud de esta tendencia, Microsoft con su nueva API DirectX 11 ha mejorado ostensiblemente el soporte multi-thereading, respecto a versiones anteriores (DirectX 9, 10, 10.1) que sólo tenían un soporte muy limitado en DX10/10.1 y sin soporte multi-thread en DX9. Ahora las tarjetas gráficas que soportan DirectX 11, que por ahora son solamente la nueva familia Radeon HD 5800s, mejoran su rendimiento, pudiendo ejecutar varias instancias al mismo tiempo, lo que significa una menor latencia en los procesos de renderizado. Por ejemplo tareas como cargar una textura y compilar un shader pueden ser ejecutadas en paralelo con el thread principal.
5 Shader Model 5.0
Dejando de lado todo lo ya antes mencionado, Shader Model 5 no trae ventajas innovadoras, sino que se enfoca en mejorar la calidad de vida de los programadores al integrar maneras mas simples y fáciles de crear código y debuggearlo, la molestia número uno a la hora de codear cualquier cosa. Para el usuario común esto significaría menos tiempo en el port de juegos de consolas a PCs (no es como si nos quedaran muchas exclusivas en el Desktop) y menos parches para corregir vulnerabilidades de algunos juegos.
Conclusiones generales.
Es sabido que NVIDIA está en desventaja en estos momentos en cuanto a tiempo respecto a AMD, que le lleva varios meses de ventaja con sus Radeon HD 5800 en el mercado y es el único en ofrecer hardware DirectX 11, por su parte Fermi le ha demandado a NVIDIA mucho tiempo y muchos recursos en el desarrollo y puesta a punto, es por esto, que liberar la información oficial antes de que el producto sea lanzado, no es algo típico de la compañía de Santa Clara, que a pesar de las filtraciones de siempre, tradicionalmente espera la fecha de lanzamiento de sus productos para liberar la información técnica asociada a sus tarjetas.
Esto de liberar información oficial antes de tiempo -siendo bien críticos y no un fanboy por que no lo soy- parece una especie de medida desesperada para calmar a la audiencia, pues a la falta de un producto ya terminado y tangible, un par de documentos con mucha información parece un buen calmante. No despreciamos este material en todo caso por que gracias a el pudimos preparar este artículo técnico para poder comprender lo que trae entre sus entrañas Fermi, aunque aun faltan cosas por averiguar.
Por otro lado luego de analizar la arquitectura, parece ser que NVIDIA podría presentar un producto bastante poderoso, ha mejorado aspectos claves como el rendimiento geométrico, agregando unidades especializadas para estos asuntos y ha hecho los cambios necesarios para soportar las tecnologías que brinda DirectX 11 y que requieren de un hardware potente -como lo es el caso de la teselacion por hardware-, ha incrementado el número de procesadores shaders o «CUDA Cores», aunque aun falta por saber a que frecuencia operaran, el hecho de incrementarlos en un 115% nos vaticina quizás velocidades moderadas compensadas por el numero de unidades. Estas mismas unidades también le ayudaran a hacer de Fermi un producto con una gran potencia de cómputo, aunque NVIDIA tampoco ha mencionado cuantos GIGA/TeraFLOPS es capaz alcanzar Fermi.
El uso de memorias GDDR5 también es una novedad, como ya dijimos hasta ahora NVIDIA se había mantenido firme con las memorias GDDR3, pero tarde o temprano tenía que migrar a este tipo de memorias que ofrecen una serie de ventajas, como menos voltaje de operación y mayores frecuencias, ahora sólo queda ver con que frecuencias de memoria vendrá Fermi.
Por sus características es posible que Fermi sea un chip grande y que tenga una basta superficie que genere bastante calor y un consumo sobre lo que hoy consume la generación actual, pero de momento estas son presunciones por que tanto información de tamaño, precio, consumo, potencia termal, disponibilidad, frecuencias y precio no han sido revelados.
AMD por su parte puede estar tranquilo pues, aunque Fermi, logre superar en rendimiento a las ATI Radeon HD 5800, la empresa puede simplemente bajar los precios de las Radeon HD 5800s para fastidiar aún mas a NVIDIA, después de todo ésta ha sido la estrategia de la compañía, cuando no ha podido superar en rendimiento a la competencia, entrega productos con buena relación precio/rendimiento, y es lo que muchos usuarios están esperando realmente, quienes no esperan que aparezca “Fermi” para comprarlo, sino que para que AMD baje sus precios y poder acceder a una producto potente, y con la mejor tecnología gráfica del momento.
Fermi por lo que vemos no tendrá la ventaja del precio, puesto que presumimos que será un producto carísimo, pero habrá que ver como lo posiciona NVIDIA en el mercado.
En lo personal, esperamos que este articulo técnico haya sido de vuestro agrado, fue un gran trabajo preparar este material y hacerlo entendible para la mayoría y en poco tiempo, esperamos que hayan llegado con los ojos abiertos hasta estas ultimas líneas por que el material era denso y requería un gran esfuerzo lector.
Sergio Castillo T.
Cedrik
39 Comment
gracias por la informacion…d nuevo…..
voi a usar este articulo pa una ivestigacion ke tengo ke hacer
jijijiji!!!!!!!!!!
gracias MADBOX
saludos!!!!!!!!!!
parece ser ke el rendimiento s bastante parejo…..
pa variar NVIDIA s mucho + cara….
me la juego por ATI………
muchas gracias por la informacion…., con un poco d paciencia
pude entender algo….
lo ke si me queda claro s ke ATI ha hecho un gran trabajo…y
NVIDIA tiene mucho por hacer aun…..
muy buen articulo Cedrik
excelente info, muy ordenada con documentacion precisa
asi cmo se viene parece que va ser las medias tarjetas, pero cmo siempre nvidia y esos 3200m de transistores me tinca que va ser muy cara y al final les va pasar los mismo que gt200 donde con la reduccion de 65nm a 55nm no fue gran cambio solo ayudo a mantener margenes minimos de utilidades
falta la 5890 =X!
tremendo articulo, un gran esfuerzo. quedo super bien explicado y felicitaciones x eso
whoaaaa! quede loco con tanta info.
gracias por el informe, completisimo, bien estructurado y facil de entender. felicitaciones y saludos.
¿Y ustedes creen que AMD no tiene una carta (o mejor dicho, tarjeta) bajo la manga para contrarrestar el lanzamiento de Fermi?
asi es, como dije AMD-ATI debe de estar en un super laboratorio monkey powered overclocked haciendo experimentos que son una afrenta a Dios.
excelente articulo
todo muy bien redactado
en mi opinion y como dice Cedrik
es posible q nvidia salga mejor q AMD/ATi
pero a su vez el precio de la ultima sera mucho mejor q su contricante
y reviviremos la guerra anterior.
gracias
Exelente articulo!
Me sobran ganas de probar un juguetito asi
yo creo que lo mas probable es que amd/ati se enfoque en el precio/rendimiento de sus productos apartir de que fermi salga a la luz. la verdadera competencia contra el rendimiento y el poder gpgpu de fermi vendría con Hecatoncheires (probablemente HD 6000 series)recordemos que ati aun no destaca en el rendimiento de gpgpu hay algunas circunstancias en donde incluso el gt200 supera al rv870 notablemente como en el caso del folding@home por citar algo. sin embargo esperemos que la pelea sea dura y la producción alta para que los beneficiados seamos nosotros.
Porfin, algo de competencia, porque a este ritmo van a bajar los precios para el 2012
muy buen articulo:) se agradece…
lo lei completo, muy buen articulo!
Me lei casi todo.
Muy buen artículo.*****
Cedrik, la proxima vez quizás debieses resumir y descartar lo menos importante, pues estoy muy consciente que te quemaste las pestañas en el artículo, por eso lo leí casi todo.
Gracias por tu esfuerzo. 🙂
voy a tener que vender un riñon si quero tener la mejor vga de nvdia directx 11 xd!
Excelente explicacion, ya habia leido un poco en otros lares, pero aca esta todo bien explicado, y mucho más detallado, me gusto el review de los papers xD
Nvidia si sera mucho más potente, y su solucion de multiples pantallas me parece mejor hasta cierto punto, si bien son 2 tarjetas,,, en ati tiene que ser una tarjeta especial, y probablemente con mayor precio que una comun..
ahora, si me gustan las geforce xDD, y creo que es solo por un apego al color vrde, asi que me tocara esperar y juntar como 300lukas, de aki a que llegue a chile, demás que ya junto.
las serie 5000 normalmente soporta 3 monitores en una sola tarjeta.
las especiales que tu mencionas (eyefinity^6) son para soportar 6 monitores a partir de una sola tarjeta.
desconocia que soportaba 3 a diferencia de las 2 por parte de nvidia, entonce bien por ati y los que ya tengan sli de geforce anteriores xD
Estoy seguro que las GF100 serán lideres en rendimiento, pero a que precio?? Seguro que a un muy mayor precio, como paso en la anterior generación, aunque ATI seguro que tendrá un AS bajo la manga, como alguna 5890 (5870 con mas clock, 1000/5000Mhz core/men)
Lo que si es seguro, es que mientras NVIDIA a estado refinando su GF100, ATI estaba ya trabajando en el futuro RV970 para que a finales de este año nos lo pongan a la venta, y cogerá en pañales a NVIDIA intentando rentabilizar su aclamado GF100.
simplemtente espectacular la presentacion de datos
felicidades cedrik por semejante trabajo
ingual se extrañaban articulos asi bien largos
Hay muchas conjeturas, que va ser un 36% mas rapida que sera uin 20% mas rapida etc. A mi lo que me interesa es que sea un buen producto y que sea ascesible, sino quedaremos igual, un buen producto por parte de Nvidia pero caro, y un buen producto por parte de ATI pero igual seguiria un precio igual al no tener competencia en su sector.
Excelente artículo. Muchas gracias MadboxPC.
Ahora más que nunca voy a esperar que salga Fermi. Estoy verde, perdón rojo, por comprarme la 5750 para reemplazar mi igfx hd4200. Esperando la rebaja de precios.
xD weena la de estas verde… =P al igual que muchos esperan solo eso…
Saludos
Fermi se ve que es muy potente, pero si nvidia quiere desbancar amd/ati en ventas, va tener que posicionar diferentes versiones de fermi con potencia/rendimiento/ por encima de la diferentes versiones de 5000 de ati a precios no muy fuera de la realidad.
Siempre he usado geforce, pero si nvidia quiere vender va tener que ser flexible esta vez, «eso espero»
siendo sincero NVIDIA tiene la forma de arreglar a Fermi en la gama media y media/alta (lo que seria la GTX 360 pero no se como hará con la GTX 380…o las vgas que correspondan a dichas gamas)
Saludos
Segun los rumores que circulan por internet, nvidia va sacar la 380 y la 360 el 10 de marzo y en abril la dual fermi algo asi como la 395..
Pero deberan sacar algo asi como la 340, 320, 310
Y entre la 360 y 380 quedara un vacio o sacaran una 375
y entre la 375 y 380 quedara otro vacio, asi sacaran 377 😀 espero que no sea como las 8800 [mas de 15 modelos] O_O
veo bien dificil que saquen una dual GF100, sobretodo por el consumo
Excelente Sergio la redacción amistosa que hiciste de una siempre complicada tecnologia de gpu
Felicitaciones
x2 Muy buena explicación
Saludos
«…y es lo que muchos usuarios están esperando realmente, quienes no esperan que aparezca “Fermi” para comprarlo, sino que para que AMD baje sus precios y poder acceder a una producto potente, y con la mejor tecnología gráfica del momento.»
Tal cual, yo soy uno de ellos, jeje, aunque ojo, todo depende a que precios salga Fermi, si Nvidia saca algún producto ganador en el sentido de precio/rendimiento al mejor estilo Intel con el Core i5 (Intel se mandó la gran AMD con el Core i5) iría por Nvidia, me dan más seguridad sus drivers…Pero, como fermi tiene pinta que va salir un ojo de la cara, espero que salga para que bajen las 58XX…Saludos 🙂
Buena info!
(conociendo las estrategias azules) Para adquirir una de estas placas, vas a tener que ahorrar una eternidad.
Seguramente cuando salga al mercado, AMD/ATI va a bajar un poco el precio de la linea 5000 y seguro de la 4800 tmb. Genial! Así hago mi Crossfire!
Excelente articulo, gracias por la avalancha de información.
aquí hay videos de fermi corriendo el bench de far cry 2
https://www.pcper.com/article.php?aid=858&type=expert&pid=9
corriendo Dark Void.
https://www.guru3d.com/article/nvidia-gf100-fermi-technology-preview/8
pienso que cuando salga fermi es definitivamente seguro que va a superar la serie 5xxx de ATI por el tiempo de salida de estas han tenido mas tiempo para estudiar a su rival, ahora ati no creo que este de brazos cruzados alguna sorpresa dará este año
Salu2.
gracias por el dato =P
Saludos
de nada 😛
Muy buena información como ya dijeron muy detallada…como siempre se espera de MadboxPC =P
Saludos
:O una informacion completisima gracias se pasaron por toda la explicacion y detalles de cada nueva generacion de vga