

Si, amigos lectores, ustedes ya lo podían sospechar: después de comparar el Athlon 64 FX-62 contra un Pentium 955 Extreme Edition, la pregunta era inmediata: ¿Y dónde está el review de ese otro monstruo?. Pues bueno, tras un largo retraso (que como toda cosa no fue 100% negativo ya que gracias a él pudimos comparar procesadores extra-poderosos de cada fabricante), por fin hoy les hago entrega de un nuevo análisis de MABOXPC, donde conoceremos a fondo las características y el rendimiento que pueden esperar de este procesador, que la gente de Intel en un amable gesto de acercarles la tecnología hasta su navegador, nos ha facilitado. No me extiendo más en agradecimientos, y los invito a ver las primeras imágenes, para que todos sepamos de quién estamos hablando.

El Pentium 955 Extreme Edition: Como todos los samples que facilita Intel, su cubierta es diferente a la de un procesador comercial, y en ella vemos las palabras «Intel Confidential»

Los 775 pads de contacto que posee este procesador, los cuales deberán tocar los pines de la placa madre dentro de la jaula del socket LGA 775
Las especificaciones técnicas de este procesador son las siguientes:
Pentium 955 Extreme Edition
-
Factor de forma: LGA775
-
Proceso de fabricación: 65nm
-
Cores: 2
-
Frecuencia: 3.46GHz
-
Memoria: Soporte DDR2 – 667 Unbuffered
-
FSB: 266Mhz (1066Mhz Quad Pumped)
-
Hyperthreading: Si
-
Cache de Segundo Nivel: 4MB (2MB por cada core)
-
Sets de instrucciones: x86, x86-64, SSE, SSE2, SSE3
-
Cantidad de transistores: 376 Millones aprox.
-
Voltaje nominal: 1.2v – 1.3375v
-
TDP: 130W
-
Tecnología de Virtualización: Sí

El sistema de ventilación que incluye Intel con este procesador: Vista superior

El ventilador + disipador: Vista lateral

La superficie de contacto del disipador, constituida de cobre.
Como podemos ver, una de las características más notables de este producto es la inclusión de 4MB de cache L2, el cual se reparte equitativamente para cada core. Esta tremenda cantidad de cache es la que hace que el número de transistores presentes sea muy grande, y sitúa al 955 Extreme Edition a la cabeza en cuanto a cantidad de caché L2 en el mercado de procesadores de escritorio. Aspectos a destacar también son la inclusión de Hyperthreading y de Virtualización (Vanderpool).
Mejor es que no les quite más tiempo en esta breve introducción y los invite a leer las dos siguientes páginas, donde aprenderemos un poco de historia y discutiremos a fondo las diversas características que agrupan a los procesadores que utilizan la misma arquitectura que nuestro sujeto de estudio actual.
Arquitectura Netburst: Antecedentes Históricos
Señoras y señores, es hora de que agarren su contenedor de plutonio, se preparen a esquivar las balas de los terroristas libaneses y estén listos para entrar al DeLorean sin olvidarse de ajustar los números en la consola del automóvil para que muestren un 2000-11-20. ¿Por qué esta fecha, antes de la paranoia colectiva en los aeropuertos, antes de la acuñación del ahora omnipresente concepto del «eje del mal», antes de que apareciera MADBOXPC, antes de que Kenita Larraín siquiera conociera a su posteriormente abandonado Bam Bam? La respuesta es muy sencilla. Ese día lunes, Óscar Senior, padre de quién aquí les escribe, se encontraba en vísperas de celebrar su cumpleaños número 46, y para eso, su aún no desmembrada familia (faltaban siete meses aún para su divorcio) le preparaba un festejo como corresponde. Aunque, paralelamente (es una de las principales gracias de que el tiempo sea multitarea, en un mismo planeta pueden ocurrir dos acontecimientos simultáneamente si no están en el mismo lugar físico (ya que si estuvieran en el mismo lugar físico y ocurrieran simultáneamente ocurriría el fenómeno conocido por los jugadores de Quake 3 Arena como TELEFRAG) ), a 12000 kilómetros de distancia, ocurría otro hecho que es el que nos interesa mayormente en esta ocasión. (No es que la víspera del cumpleaños número 46 de mi padre sea algo intrascendente para mí, pero bueno, en esta ocasión es algo que está ligeramente off topic con respecto al título de este artículo). Dejémonos de monadas, y por consiguiente, de irnos por las ramas, para acotar mis tecleos a escribir del acontecimiento que a 12000 kilómetros de la casa de mi padre ocurría: En los cuarteles generales de Intel se lanzaba oficialmente un procesador utilizando el core Willamette, que daba inicio al uso de la tecnología Netburst por parte de Chipzilla, y que daba inicio también a la generación Pentium 4.
¿Netburst? Si, con ese nombre nos referimos a la séptima generación de procesadores de Intel, que venía a relevar a la conocida como P6 (que llevaba existiendo desde 1995) y que hasta el día de hoy (aunque faltan pocos meses para la aparición de la octava generación de procesadores Intel, conocida como Core, y que tiene como bandera el flamante Conroe) es la que podemos encontrar en los procesadores que produce Intel, a excepción de los Pentium M y los Yonah, que aún utilizan estructuras de sexta generación.
¿Y cual es la gracia de Netburst? Las características principales que incluye son tres:
Tecnología Hyper Pipelined (Hyper Pipelined Technology):
Imagínen una línea de producción de una fábrica: una cinta continua donde pasan piezas, y donde delante de ella hay un número determinado de robots (o de obreros, si queremos combatir el desempleo) que cogen la pieza que pasa delante de ellos, realizan una tarea determinada sobre ella, y la vuelven a dejar en la cinta, para que el robot que sigue en la línea le vuelva a hacer otra cosa diferente, y así sucesivamente, hasta que la pieza pasa por el último robot frente a la cinta, y el producto está terminado. ¿Esto lógicamente es más rápido que tener a un sólo robot armando los productos uno a uno, no? Pues bien, en arquitectura de procesadores, diseñar algo análogo a lo recién descrito que sirva para ejecutar las instrucciones que pasen por el procesador, se llama utilizar la técnica del pipelining. Como les contaba, de buenas a primeras, se ve mucho más eficiente tener un pipeline que ejecute las instrucciones separadas en distintas etapas, que a tener una sola etapa más larga que haga todo; pero, obviamente hay que tener siempre presentes que todo proceso tiene sus desventajas, y el pipelining tiene la desventaja (en términos simples) que si en una de las etapas pasa algo malo, el resto de las etapas siguientes lógicamente no pueden seguir procesando la instrucción y hay una pérdida de tiempo. (Esta situación la podemos analogar a cuando el típico obrero gringo de las películas se quedaba dormido frente a la línea de montaje, causando con eso un desastre y un atochamiento que perjudicaba a todos los obreros y no sólo a su etapa en específico.
La tecnología Hyper Pipelined nos propone inicialmente la utilización de un pipeline de 20 etapas, lo que es una cantidad bastante grande si tenemos en cuenta que el pipeline de los Pentium III tenía solamente 10. Así, las instrucciones pasan por el doble de pasos antes de poder resolverse por completo (aún más, en los Prescott, procesadores Netburst que aparecieron a inicios del 2004, la cantidad de etapas se aumentó a 31, siendo entonces más del triple de pasos los que tenían que recorrer las instrucciones en comparación a un Pentium III) lo que inmediatamente hace que pensemos en que una «línea de montaje» demasiado larga puede ser ineficiente, ya que las cosas se demoran más al pasar de mano en mano y con eso se genera una pérdida de productividad. Pero bueno, el gigante azul siempre tiene una respuesta para todo, y en esa época aseguraron que se compensaba la pérdida de rendimiento debido al largo del pipeline con la utilización de velocidades de reloj (que aquí vienen a representar al negro que le pega al tambor marcando la cadencia) mucho más altas (prometieron llegar hasta los 10Ghz, LOL), lo que era permitido en palabras simples por la menor complejidad de las etapas. Alguna coherencia tiene ese argumento, pero de todas maneras levanta suspicacias, ya que si fuera tan simple la cosa, sería mejor tener un pipeline de 1000000 etapas donde cada etapa la pudieramos realizar muy rápido. El problema con eso es que siempre hay una pérdida de tiempo asociada a cada etapa (representada en nuestro ejemplo por el tiempo que el robot pierde en levantar la pieza de la cinta y en volverla a dejar una vez realizada la tarea correspondiente), así que al aumentar el número de pasos en demasía esa pérdida se acentúa haciéndonos que todo ande peor. Por supuesto, siempre hay un punto de equilibrio y de máximo rendimiento donde la duración y número de los pasos a realizar se compensa con las pérdidas inherentes de tiempo, pero en esta ocasión todo el mundo del hardware levantó la ceja ante la inclusión de estas nuevas características ya que por lo que se veía, el número de etapas elegido por Intel no era precisamente el número del equilibrio.
Además de esto, ante la utilización de este pipeline tan largo, surgía otra duda aún mayor y que podría hacer que el rendimiento de los procesadores fuera desastroso: ¿Que pasaba en la fábrica del ejemplo cuando uno de los robots cometía un error (cosa probabilísticamente probable)? Todo el resto de robots que lo seguían quedaban parados con las manos vacías esperando a que el tarado volviera a recibir otra pieza. Entonces, ¿que pasa cuando se tiene una cadena con muchos robots?. De inmediato vemos que la posibilidad de un error al ser muchos los participantes aumenta sideralmente; un ejemplo clásico es el que calcula que para que sea casi 100% seguro que en una habitación hayan dos personas de cumpleaños el mismo día no necesitamos que te
ngamos apretujadas a 364 personas, sino que solamente con 60 personas o más la probabilidad de un cumpleaños simultáneo salta al 99%. Bueno, lo mismo pasa al incorporar más y más etapas, la probabilidad de un error y de una consecuente pérdida de tiempo aumenta, además de que la recuperación de un error mientrás más pasos tenga el proceso es mucho más lenta.
Motor de Ejecución Rapida (Rapid Execution Engine):
Esta característica permite que la unidad aritmético-lógica (la ALU, parte del procesador encargada de resolver las operación aritméticas y lógicas; hay ALUs que se encargan de operar con los enteros, otras con los números en coma flotante) funcione muchísmo más rápido que antes; si en generaciones anteriores de procesadores la ALU corría a la misma velocidad del procesador, en Netburst funciona al doble de velocidad. Eso permite que las operaciones en enteros se resuelvan en mucho menor tiempo con respecto a otras arquiteturas; pero trae el efecto indeseado de que algunas operaciones que en P6 andaban de maravillas aquí anden por los suelos.
De todas maneras, se supone que el motor de ejecución rápido permitía sobreponerse a la baja cantidad de instrucciones por clock que causaba el elevado número de etapas del pipeline de instrucciones.
Cache de seguimiento de ejecución (Execution Trace Cache):
La gracia de este Cache es que almacena datos, pero no datos propiamente tales, sino que agarra pequeñas operaciones (las que unidas de distinta manera entre si conforman las instrucciones) y las almacena decodificadas y enteritas. Esto es una optimización bastante importante, ya que pasos fundamentales del pipeline son traer una instrucción codificada desde la memoria y luego decodificarla; gracias al Execution Trace Cache en vez de pasar obligadas por esas dos etapas, se arman a base de estas pequeñas microoperaciones ya decodificadas, y las cuales además son mucho más rápidas de acceder que desde la memoria principal.
Además de esas tres características principales, la arquitectura Netburst incorporó desde su primer core (Willamette) el juego de instrucciones para datos paralelos SSE2; desde la aparición del core Prescott se incorporó SSE3 y en revisiones posteriores de ese core se activaron las extensiones para 64bit EMT64. Además, Prescott (como les adelantaba un par de párrafos antes) alargó las etapas del pipeline de instrucciones a 31, así como también dedicaba una extensa zona del core a circuitos que se suponía mejoraban el branch prediction (que en pocas palabras es cuando al trabajar con una instrucción se deben elegir entre varias opciones (el típico IF-THEN-ELSE es un buen ejemplo) y resulta conveniente para el rendimiento tratar de «predecir» la opción correcta; obviamente una predicción siempre es susceptible de fallar, y cuando habían errores de predicción era precisamente ese momento que antes les describía en términos simples como un «error en el pipeline», y que conllevaba una gran pérdida de tiempo, ya que todos los datos que esperaban detrás debían vaciarse del pipeline y comenzar todo de nuevo), que ahora debido a la enorme cantidad de etapas del pipeline se hacía imprescindible.
Las diferentes revisiones que tuvo la tecnología Netburst fueron las siguientes: La inicial Willamette, que estaba construida con un proceso de 180nm; Northwood, lanzada a principios del 2002, que incluía una mayor cantidad de caché, un pipeline aumentado de 20 a 21 etapas y que estaba fabricada con proceso de 130nm y además incorporaba la nueva tecnología Hyperthreading, de la que les hablaremos en unas páginas más. Un año y medio después, una semana antes del lanzamiento de los Athlon 64 – Athlon FX por parte de AMD, fue anunciado el core Gallatin, destinado a ocupar las placas madres de los comsumidores más adinerados, ya que sería utilizado en los procesadores Pentium 4 Extreme Edition. Sú única gran diferencia con respecto a Northwood era que incluía por primera vez Cache de tercer nivel (2MB); el cual no presentaba mejoras evidentes en el rendimiento de todas las aplicaciones, sólo en algunos juegos se veían diferencias notorias con respecto a un Northwood y los rumores indicaban que fue un lanzamiento desesperado para intentar contrarrestar el lanzamiento de los nuevos Athlon64, que se suponía marcaría una diferencia notable de rendimiento para AMD. En 2004 fue lanzado el ya mencionado Prescott con tecnología de 90nm, que incluía todo lo descrito en el párrafo anterior; por estas características Prescott tuvo enormes problemas ya que consumía muchísima energía y generaba cantidades de calor industriales, que lograron conseguirle el bien merecido apodo de la «estufa» o el «Pres-hot». Estos mismos problemas son los que impidieron que Intel lograra los altos clocks (les recuerdo los 10Ghz, LOL de nuevo) que prometía en los primeros días de esta tecnología. Luego del lanzamiento de Pescott, era hora de los dual cores, y rápidamente, en Mayo de 2005 (días antes del lanzamiento del Athlon X2) puso en el mercado el core Smithfield, que era la versión Dual Core de Prescott. Hablaremos de estos procesadores en la próxima página, así que continúo con el último core solitario que lanzó Intel ocupando Netburst, y que es Cedar Mill, con un proceso aún más pequeño de 65 nm (lo más pequeño en el mercado actual), y que conocimos a principios del 2006. Para finalizar, también a principios de 2006 se lanzó la versión dual de Cedar Mill, conocida como Presler, que es la que lleva dentro el procesador que analizaremos en estas páginas, y del cual hablaremos extensamente en la próxima página, la cual invitamos a leer.
Pentium D? Core Presler?
Ya que en la página anterior hablamos a muy grandes rasgos de como funcionan básicamente los procesadores que contienen la tecnología Netburst, en este mini capítulo explicaremos de la manera más simple posible las características más importantes de la línea de procesadores Pentium D, línea a la que pertenece el 955 Extreme Edition.
En el foro de desarrolladores de Intel de 2005 (en su versión primaveral), la gente del gigante azul hizo el anuncio del lanzamiento de los primeros procesadores Dual Core para el mercado casero. (No olvidemos que varios años antes, IBM había lanzado el primer procesador Dual Core, el POWER4, el cual estaba orientado al segmento de servidores). Inmediatamente se comenzó a especular de la manera en que Intel lograría construir estos procesadores; en ese entonces los procesadores que se producían utilizaban el core Prescott, que como bien hemos dicho generaban una cantidad de calor tal que servían hasta para freir un huevo encima. Además, tampoco se sabía a ciencia cierta si es que los nuevos procesadores estarían construidos sobre un solo pedazo de silicio o serían dos los dies que estarían debajo del IHS. Esa duda fue rápidamente despejada por Intel, que mostró que los procesadores dual core que estaba lanzando estaban construidos sobre un pezado de silicio tamaño gigante, en el cual habían impresos dos cores Prescott pegados indisolublemente uno al lado del otro. Además de eso, para intentar combatir los enormes requerimientos de consumo y la gran cantidad de disipación térmica que debía de producirse teniendo en cuenta que ahora eran dos las estufas que estaban dentro del mismo empaque, Intel incluía el sistema de administración de consumo SpeedStep, así como también las tecnologías C1E, TM2, y EIST que se supone que ayudarían a evitar los incendios y bajarían algunos millones de pesos nuestra cuenta eléctrica.

El core Smithfield, donde podemos ver que sólo un pedazo de silicio contiene los dos cores.
Pero bueno, como no todo puede ser maravilloso en este mundo, un problema de diseño empañaba lo bonito de lanzar un producto dual core para el usuario común y corriente: ya que Intel no concibió su tecnología Netburst desde un principio como una tecnología preparada para el uso de más de un core, al tratar de instalar dos cores en un mismo procesador se vio obligado a intercomunicarlos mediante el bus frontal del sistema. Si, el mismo bus frontal que debe comunicar un procesador con el northbridge ahora también debe hacerse cargo de realizar todas las comunicaciones intercore. ¿Y cual es el problema de esto? bueno, si ustedes revisan las specs de los primeros Pentium D, verán que el bus frontal que soportan estos procesadores es de 800Mhz (200Mhz Quad Pumped), es decir su ancho de banda es de 6.4Gb/s, lo que queda muy, pero muy corto con respecto a las velocidades máximas que puede alcanzar el Cache L2 (13 Gb/s, imagínense al L1, que es aún más rápido). Aunque siempre los gallos se ven en la cancha, así que no nos deprimamos por esta deficiencia estructural y sigamos adelante.
Ahora que ya conocemos bien al precursor de nuestro amigo 955 EE, es hora ya de que pasemos unos meses más adelante en la historia, y nos situemos en los primeros meses de este año en curso, 2006. Es aquí donde Intel nuevamente nos sorprendió al lanzar los primeros procesadores construidos bajo proceso de 65nm, lo que significaba una nueva disminución en el proceso y sonrisas de felicidad en la cara de los overclockeros que veían la posibilidad de llevar aún más al límite sus procesadores. Y junto con este anuncio, se renovó la línea Pentium D con la aparición del core Presler (¡si, por fin, el que nos interesa!), que consistía en un par de Cedar Mills uno al lado del otro. Y aquí nótese, hay una diferencia bastante grande con respecto a su antecesor Smithfield: léase clarito «uno al lado del otro» y no «pegado al otro«, ya que en esta ocasión el procesador consistía de dos cores separados, montados sobre la base; a uno le surje de inmediato la pregunta respecto del porque de esta decisión, y bueno, la respuesta es bastante sencilla: tal como se imaginan, el trabajar con proceso de 65nm significa de inmediato que los cores de los procesadores son de tamaño más pequeño (si se mantiene el mismo diseño con respecto a sus hermanos de 90nm, lo que precisamente ocurre, ya que Cedar Mill no es más que una versión miniaturizada de Prescott), lo que redunda en que del pedazo de silicio del cual se obtienen los cores (conocido como wafer u oblea de silicio) se puede obtener una cantidad mucho mayor de ellos (aplicando la relación básica de «si es más chico caben más en el mismo tamaño»). Este mayor rendimiento (en cuanto a superficie) ya significa de inmediato más utilidades a futuro, pero aún podemos lograr que la cosa rinda más: también es sabido que es imposible que de una oblea TODOS los core salgan buenos; suelen producirse varios ejemplares defectuosos que implican una pérdida de material. Entonces, si en vez de fabricar cores gigantescos que en realidad son dos cores pegados entre sí fabrico cores individuales que después van unidos, pero a nivel de procesador y no de silicio, lógicamente cuando ahora se produzca un core defectuoso sólamente voy a perder el pedazo correspondiente a un sólo core y no el pedazo más grande de los dos cores pegados. ¿Rendimiento=dinero, no? Intel sabe muy bien eso, y es principalmente por esa razón que decidió separar los cores dentro de los procesadores núcleo Presler. Aún a costa de perder una pequeñita cantidad de rendimiento, porque la distancia que deben recorrer los datos entre core y core es ahora ligeramente mayor.

Core Presler: Aquí los dos cores van separados en la empaquetadura y son piezas de silicio distintas.
De todas maneras, en el resto de sus capacidades, Presler sigue siendo nada más que un par de Prescotts achicados , pero con la adición de soporte para VT (Virtualización, también llamada por Intel como Vanderpool Technology). Un detalle importante y en el que nos extenderemos un poco más adelante es el hecho de que los modelos EE (Extreme Edition, 840 en core Smithfield y 955 o 965 en core Presler) también permiten la utilización de HyperThreading.
Hyperthreading: cuando uno se transforma en dos ¿O no?
Intel ha sido el primer fabricante en lanzar un procesador de escritorio que implemente multithreading simultáneo (SMT, Simultaneous Multithreading). ¿Qué es esto? El multithreading simultáneo es una técnica que deja de lado la concepción tradicional de que un procesador corra un programa de manera «líneal«. Un buen ejemplo de esta manera líneal es la siguiente: «Tengo que pintar cuatro murallas, que llamaré A, B, C y D, dándole tres manos de pintura a cada una. Lo primero que hago es darle una mano de pintura a la pared A. Espero unas horas hasta que esté seca, y le doy la segunda mano. Espero otro par de horas, y cuando esté seca esta segunda mano, le doy la tercera mano. Ahora que tengo completamente terminada la pared A, voy a la pared B y le doy una primera mano de pintura. Me siento hasta que la pintura se seque y le doy la segunda mano… sigo esperando y cuando está seca le doy la tercera mano a la pared B, con lo que la termino. Ahora es el turno de la pared C, que pintaré de la misma manera, y una vez que la termine, iré a la pared D, que una vez que reciba sus tres manos estará lista y con esto terminaré toda la tarea».
Como pueden suponer, este sistema de trabajo es bastante ineficiente, ya que hay mucho tiempo perdido que podría aprovecharse haciendo algo. Lo que el multithreading simultáneo propone como solución de esta tarea sería: «Le doy la primera mano a la pared A. Mientras se seca, doy su primera mano a la pared B, y luego a la C y a la D. Con lo que he tardado en pintar las primeras manos de las cuatro paredes, la pared A ha secado, así que doy su segunda mano. Al terminar la segunda mano de la pared A veo que la pared B también ha secado, asì que la pinto nuevamente, y luego a la C y a la D, que también han secado. Después de esta segunda mano, con lo que tardé en pintarlas todas la pared A ha vuelto a secar, estando lista para su tercera mano, la que doy y luego sigo con B, C y D. Tarea terminada, y en muchísimo menor tiempo que con el sistema de trabajo anterior». Así, aprovechamos los inevitables tiempos muertos para seguir avanzando en la ejecución de otras partes del proceso. ¿Será efectivamente «más mejor» trabajar de esa manera?
El Hyperthreading tuvo sus inicios en el Superthreading, otra manera de realizar SMT que consistía en algo bastante simple análogo a lo del ejemplo anterior: En cada ciclo del procesador, se saltaba de un thread a otro para ir resolviendo las distintas instrucciones. Con eso, los ciclos que se perdían al trabajar con solamente un thread (imagínense por ejemplo cuando un thread necesita acceder a memoria; todo el tiempo de latencia que se pierde accediendo para leer o escribir en la memoria principal son ciclos de reloj perdidos) se podían aprovechar de mejor manera agarrando otros thread que estaban listos para ser ejecutados.
Específicamente, lo que hace HT es duplicar la parte del procesador que se encarga de almacenar el estado en que se encuentran los procesos (esa parte se conoce como «architectural state«, y contiene todos los registros de control y los registros de uso general), sin duplicar las asignaciones de recursos de ejecución. Así, cuando el procesador se encuentra «perdiendo tiempo» (por ejemplo en esos momentos en que ocurre un error de predicción, ya descritos unas páginas atrás y conocidos como «branch misprediction«, o cuando se falla en leer o escribir en el cache, lo que implica una gran perdida de tiempo accediendo a la memoria principal, y que se conoce como un «cache miss«, o cuando un thread necesita de la información de una instrucción que aún no se acaba de ejecutar, cosa que se conoce como «data dependency«), el procesador puede utilizar estos recursos de ejecución en otra tarea. Lo ùnico que necesitamos para que esta «maravilla» (las comillas son porque varios dicen que no es tanta la «maravilla») funcione es tener un sistema operativo que soporte HT (Windows XP por ejemplo) y aplicaciones que estén diseñadas para correr con múltiples hilos, lo que significa que aplicaciones antiguas o no diseñadas para SMT no sacarán partido de esta característica (lo que también sucede con un procesador Dual Core, si la aplicación en específico no está diseñada para procesar en paralelo, olvidémonos de mejoras en el rendimiento)
Lo que Intel promete como mejora en el rendimiento de un sistema que utilice Hyperthreading es un 30% con respecto a un procesador de similares características sin soporte HT. Esto ha sido materia de debate intenso en el circuito tecnológico, donde se ha dicho que el HT a veces incluso puede PERJUDICAR el rendimiento de un sistema. Intel, por su parte, también «avisó» que una aplicación programada para procesamiento serial al ser corrida bajo HT aumenta su complejidad de ejecución. Como nosotros no nos quedamos con la opinión de otros, vamos a probar en «terreno» la real utilidad del Hyperthreading y así poder despejar los mitos en cuanto a su utilidad y o perjuicio.
Un hecho bastante curioso es que a pesar de que el Hyperthreading fue desarrollado y utilizado en los procesadores con arquitectura Netburst, su uso en la próxima generación de procesadores de Intel, Intel Core Microarchitecture, al parecer será descontinuado. ¿Razones de esto? Algunos esgrimen que consumía más energía de los beneficios que producía. En realidad tenemos que esperar a ver que nos dice el tiempo, pues aún cuando Justin Rattner, CTO de Intel afirmó que HT era una tontería debido a la fuerza que estaban teniendo los sistemas multicore, el beneficio que entregan en determinadas aplicaciones (sigan leyendo este review y se enterarán) no deja de ser importante.
¿Subir clocks? ¿En un tope de línea? ¡Vamos!
Me da muchísimo gusto poder dedicarle una página de este review exclusivamente al tema del overclock; es bastante favorable que Intel, que nos ha prestado este procesador para su revisión, tenga una política bastante amigable con respecto al overclock; política que se puede resumir en «Do you wanna overclock it? Overclock it all the way you want!» y que nos permite llevar a ustedes resultados realmente extremos y que no siempre se ven en todos lados. Sería hermoso que todos los fabricantes de procesadores tuvieran esta actitud, pero bueno… nadie es perfecto.
El hecho de que Intel haya empezado a lanzar procesadores construidos con proceso de 65nm, tal como decía unas páginas atrás, es algo que a los overclockeros extremos de todo el mundo no deja indiferente. Cada vez que hay una reducción de proceso, las expectativas de overclock de los procesadores crecen más y más, y si sumamos a eso que la arquitectura Netburst está hecha para correr a muy altos Mhz (con la gran desventaja del calor generado y el consumo de energía) tenemos fiesta segura. Si buscamos a través de la «Interweb» los resultados que obtienen los overclockers de más renombre en todo el globo, veremos que hay récords tan impresionantes como 7.11Ghz SuperPI 1M estables (claro que utilizando sistemas de enfriamiento realmente extremos como Nitrógeno Líquido (falta muy poco en nuestro querido país para que empecemos a ocupar sistemas de este tipo) o Cambios de Fase en Cascada).
Pero bueno, acá aunque no juguemos con nitrógeno líquido de todas maneras podemos ofrecer buenos resultados. Para buscar el mayor overclock posible, en primer lugar intentaremos encontrar la mayor velocidad estable 100% con el voltaje stock y refrigerando a stock; finalmente utilizando un equipo de cambio de fase y luego un tubo de hielo seco intentaremos llegar a los mayores clocks posibles donde podamos correr SuperPi 2M.
Una de las ventajas más importantes de pagar el precio que cuesta un procesador EE de Intel es el hecho de que nos encontramos ante un equipo con el multiplicador desbloqueado, lo que nos permitirá ir tanteando rápidamente el techo del procesador, a la vez que no necesitaremos forzar tan brutalmente el bus del sistema. Inicialmente este procesador viene configurado para correr a 266×13 Mhz, lo que equivale a 3.46Ghz. Es cosa de subir solamente el multiplicador a 14x para quedar funcionando 100% estable a 3.73GHz (velocidad nóminal de un Pentium 965 EE, actual tope de línea de Intel), o a 15x, para casi tocar los 4Ghz, quedando a 3990Mhz. La cosa se ve muy fácil, simple y bonita todavía, ya que debido al multiplicador desbloqueado aún no hemos tenido que tocar un solo pelo del resto de las configuraciones, permaneciendo el bus del sistema y las memorias completamente intactas. Lo mismo ocurre con los voltajes de CPU y Chipset, que no han sido modificados.
Seguimos probando con el multiplicador, y al aumentar a 16x llegamos a la nada despreciable cifra de 4.26Ghz, pero con la tristeza de que no podemos correr todos los benchmarks, ya que pruebas como el CPU Test del 3DMark06 se cuelgan sin remedio.
Llega la hora de empezar a manejar settings, y finalmente, después de algunos horas de trabajo, llegamos a la máxima configuración 100% estable con refrigeración stock y sin aumentar los voltajes por defecto: 295×14=4130Mhz. ¿Nada mal, eh? 672 Mhz de overclock por aire, sin mover voltajes y en un procesador tope de línea. Nada menos y nada más que un 19,43% de overclock. Muy interesante.

CPU-Z mostrándonos información acerca de nuestro máximo overclock 100% estable por aire

La información del mismo overclock, pero ahora relativa a las memorias
Ya que pudimos obtener esta configuración 100% estable, será la que utilizaremos en nuestras pruebas para ver el aumento de rendimiento con respecto a los clocks de fábrica.
Pero bueno, no habríamos dedicado uná página completa al overclock si es que fueramos a llegar sólo hasta acá. Una de las cosas de las que me pude dar cuenta al overclockear por aire era que el potencial del procesador era impresionante, nada impedía que siguiera subiendo de velocidad hasta el cielo… nada excepto la temperatura. Muy reducción de proceso a 65nm será, pero el origen Prescottiano de este Dual Core es una especie de Karma Térmico que no podemos dejar de lado: muchas de las configuraciones de oc por aire a voltajes superiores que tuve que desechar tuvieron que ser descartadas por la enorme cantidad de calor que generaban. Más de un susto pasé cuando realizando tests que estresaban el procesador al máximo, de pronto todo se iba a negro y al encender de nuevo me daba cuenta de que el sistema de protección de sobrecalentamiento de la placa había evitado un desastre sin remedio. Bueno, el overclock es un deporte arriesgado, así después de eso era cosa de esperar un rato a que el disipador se enfriara y seguir probando otra configuración.
Lo que podía concluir de todo esto era que si lograba enfriar el procesador más allá de lo que estaba logrando hasta el momento, los resultados que obtendría serían mucho mejores; y es por esto que me animé y dí mis primeros pasos en el overclock extremo intentando mejorar los resultados mediante un equipo de cambio de fase, y posteriormente refrigerando con hielo seco.
La cosa ahí era muy diferente. Si antes no podía subir de voltaje por el problema termal que se me generaba, utilizando el cambio de fase o el tubo de hielo seco ese problema desaparecía en gran medida. Después de toda una tarde jugando al heladero y rellenando constantemente el tubo en busca de más y más frío, pude llegar al máximo resultado estable en esas condiciones: 300×18=5400Mhz. Ahora ya no son sólo 672Mhz, sino que estamos hablando de overclockear el procesador la ínfima cantidad de 1935Mhz, ¡CASI 2Ghz por sobre la velocidad nominal del CPU! A estas alturas de lo que hablamos es de un 56,16% de aumento, lo que es una cantidad, a mi parecer, sencillamente notable. Solo despues nos faltaba configurar adecuadamente las memorias para lograr el máximo rendimiento posible, y después de unos cuantos intentos, a DDR2 900, 4-4-4-12 las Corsair 5400UL entregaban lo mejor de si mismas.
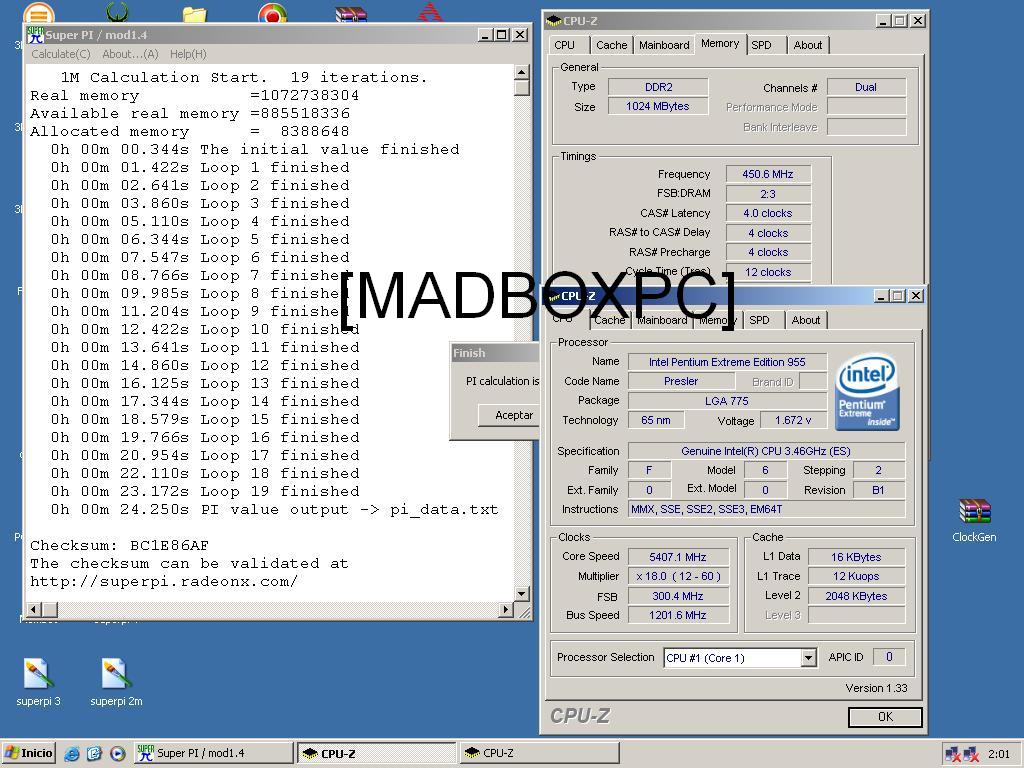
Super PI 1M, Overclock a 5400Mhz usando Hielo Seco (D-ICE)

Super PI 2M, Overclock a 5400Mhz usando Hielo Seco (D-ICE)
¿Qué nos impidió seguir subiendo? La manera de entregar voltaje de la placa madre (una ASUS P5WD2 Premium), que no fue vcore moddeada, hacía que nos entregara siempre casi 0.5v menos de lo que correspondía; al poner la carga del CPU 100% el voltaje decaía aún más y este problema (conocido en la jerga overclockera como vdrop) lo hubieramos solucionado de haber realizado un vdrop mod en la placa. Y hablando de voltaje, la fuente de poder ya comenzaba a ser un obstáculo en nuestra misión, ya que la poderosa PSU Delta facilitada por Intel ya estaba mostrando señales de agotamiento extremo y ninguna otra fuente a disposición de MADBOXPC soportaba la carga de este procesador a esos clocks y esos voltajes.
Otro factor importante que disminuyó nuestras posibilidades fue nuevamente la temperatura; con la configuración que trabajabamos ni siquiera el tubo de hielo seco daba abasto y la temperatura se mantenía muy alta para esas condiciones, entre -1ºC y 3ºC. Otro gallo hubiera cantado si hubieramos tenido acceso a algún sistema más extremo de refrigeración, pero bueno, en Chile de todas maneras se avanza a pasos agigantados en este mundo. Quién sabe que sorpresas tengamos para ustedes cuando analizemos la próxima bestia que Chipzilla prepara para lanzar al mercado (Conroe, here we go!)
En todo caso, creo que este es uno de los únicos reviews en el mundo donde llevamos hasta este extremo un procesador. Todo un orgullo para MADBOXPC, que cada día está más grande y lindo. No más spam en nuestra propia casa y sigamos con el review. Las pruebas nos esperan.
Plataforma y metodología de pruebas

Hardware
-
CPU Pentium 955 Extreme Edition core Presler
-
CPU Athlon 64 FX-62 socket AM2 core Windsor
-
MB ASUS P5WD2 Premium (Chipset 955x)
-
MB M2N32 – SLI DELUXE (Chipset Nforce590)
-
VGA ATI Radeon X1800XT
-
MEM Corsair XMS2 5400UL
-
HDD Seagate 200Gb SATA
-
PSU Delta Electronics DPS 600MB Rev01
-
PSU Thermaltake TR2-500W
Comentario al margen: Intel nos había facilitado para la revisión de este procesador una placa madre INTEL D975XBX i975x, la cual lamentablemente durante su operación falló por lo que tuvimos que reemplazarla de nuestra plataforma de pruebas con una de nuestras placas. (Viste que somos caballeros, eh, tu ya sabes quién?)
Software
-
Windows XP SP2
-
Catalyst 6.4
-
Cpu Z 1.33
-
WinRAR 3.11
-
DVDShrink 3.2
-
VirtualDubMod 1.5.10.2 (build 2540/release)
-
Adobe Photoshop CS
-
Super PI mod 1.4
-
Reason 3.0 build 5.14
-
Sisoft Sandra Lite 2005.SR3
-
Quake 4 v1.0.5 Beta Patch
-
F.E.A.R. v1.0
-
CINEBENCH 9.5
-
FutureMARK 3DMArk03
-
FutureMARK 3DMark05
-
FutureMARK 3DMark06
-
FutureMARK PCMark05
Para las pruebas utilizamos tres configuraciones de procesador: Velocidad Default (266×13=3458 Mhz) con memorias a DDR2 667 4-4-4-12 (aunque las memorias permitían estrechar aún más las latencias, preferimos ocupar un juego de latencias típico de DDR2 para mostrar el rendimiento del procesador sin que las memorias se constituyan como la estrella del review); Máximo Overclock por aire (295×14=4130Mhz), con memorias a DDR2 740 4-4-4-12, y Velocidad Default (266×13=3458) con memorias a DDR2 667 4-4-4-12 pero con Hyperthreading Desactivado.
Como comparativa utilizaremos la configuración default del procesador FX-62 (200×14=2800Mhz), con memorias corriendo a DDR2 800 4-4-4-12. No incluimos pruebas con overclock debido a que AMD no promueve la práctica del overclock con sus procesadores.
La metodología de pruebas de las pruebas multitarea aparece en su sección correspondiente.
La metodología de las pruebas que realizaremos será la misma que empleamos en el análisis del AMD Athlon 64 FX-62, al que hemos llegado después de largas discusiones sobre el tema y que hasta nueva actualización será nuestra configuración oficial para analizar procesadores MadboxPC Certified. De todas maneras, les entregamos los detalles de nuestro sistema de pruebas para que puedan observar, discutir y aprender.
-
Para testear WinRAR hicimos dos pruebas: comprimimos mediante el método de compresión estándar de WinRAR una colección de 528 carpetas y 10464 archivos de 1,61Gb de tamaño, y comprimimos mediante el mismo método el archivo VTS_01_1.VOB producido por la compresión efecutada con DVDShrink. Los archivos se llamaron RARSAMPLE.RAR y VTS_01_1.RAR. Se tomaron las horas de creación y de última modificación de cada archivo.
-
Con DVDShrink cargamos un ISO de la película BEFORE SUNRISE, mediante DAEMON TOOLS, y procedimos a su compresión. La película principal y los extras (excepto menús) fueron comprimidos a un 50%. Se realizó el análisis previo del DVD sin considerar el tiempo de duración de éste. Se activaron las mejoras exclusivas de DVDShrink, ajustánd
ose en Nítida (Estándar). Se desactivó la casilla que fija la prioridad de la compresión en baja. El software entrega al final el cálculo del tiempo utilizado en la tarea. -
En el caso de la compresión mediante DivX, utilizamos el software VirtualDubMod, en el que seleccionamos el modo Fast Recompress. En la configuración del códec se activó la opción Enhanced Multithreading. El archivo comprimido fue el archivo VTS_01_1.VOB producido por la compresión efecutada con DVDShrink. Para el cálculo de tiempo se utilizaron la hora de creación y de última modificación del archivo.
-
Una imagen de 8000×6000 pixeles fue la utilizada para medir el rendimiento en Adobe Photoshop CS. El filtro aplicado fue Desenfoque Radial, ajustando en Cantidad 100, Método Giro y Calidad Óptima. La duración de la tarea se midió con cronómetro.
-
Para medir Reason se rendereó a WAV una composición musical, utilizando frecuencia de sampleo de 96000Hz, profundidad de 16bits y dither activado. El tiempo se calculo mediante la diferencia entre la hora de última modificación y la hora de creación.
-
En Sisoft SANDRA no se hicieron cambios de ningún tipo en la configuración. Para SuperPI se corrieron las pruebas correspondientes a 1M de digitos.
-
En PCMark05 y 3DMark03,05,06 se utilizaron todos los ajustes por defecto.
-
Cinebench corrió el CPU Benchmark, en su modo 1 CPU y X CPU, sin modificar ninguna otra configuración.
-
En F.E.A.R. se ejecutó el test de rendimiento incorporado en el juego. todas las opciones gráficas estaban configuradas en Maximum, a excepción de los filtros Antialiasing y Anisotrópico, y de Sombras Suaves, que fueron desactivadas. La resolución utilizada fue de 1024×768.
-
Para finalizar, en Quake 4 fueron ejecutados los archivos DEMO1.DEMO y DEMO4.DEMO en modo timedemo. Se hicieron pruebas también con el modo SMP activado y desactivado. Se activaron todas las opciones gráficas, a excepción de los filtros antialiasing y anisotrópico. La calidad de las texturas se fijó en Ultra. La resolución ocupada fue 1024×768.
Benchmarks Sintéticos: SANDRA, SuperPI, 3DMarks, PCMark, Cinebench
Un puntaje bastante bueno, vemos que con overclock las cosas mejoran casi en un 12%. El rendimiento con respecto a su contraparte AMD es el mismo, teniendo ante nosotros un empate técnico. (Un 0.45% de ventaja para el FX-62)
La gran influencia de la VGA en esta prueba es la responsable de los resultados que tenemos: El aplicar overclock casi no mejora los resultados. A velocidad stock la ventaja la tiene el FX-62, aunque sólo por un 1.51%. El overclock invierte el podio, pero de todas maneras los resultados son bastante similares.
Aquí los resultados son favorables al procesador AMD por un 11.36%. Ni todo el overclock que permite hacer el 955 EE permite revertir esta situación.